在生产环境中需要管理运行着应用程序的容器,确保服务不会下线。Kubernetes 提供了一个可弹性运行分布式系统的框架,它也是自动化容器操作的开源平台,这些操作包括部署,调度和节点集群间扩展。
#环境搭建
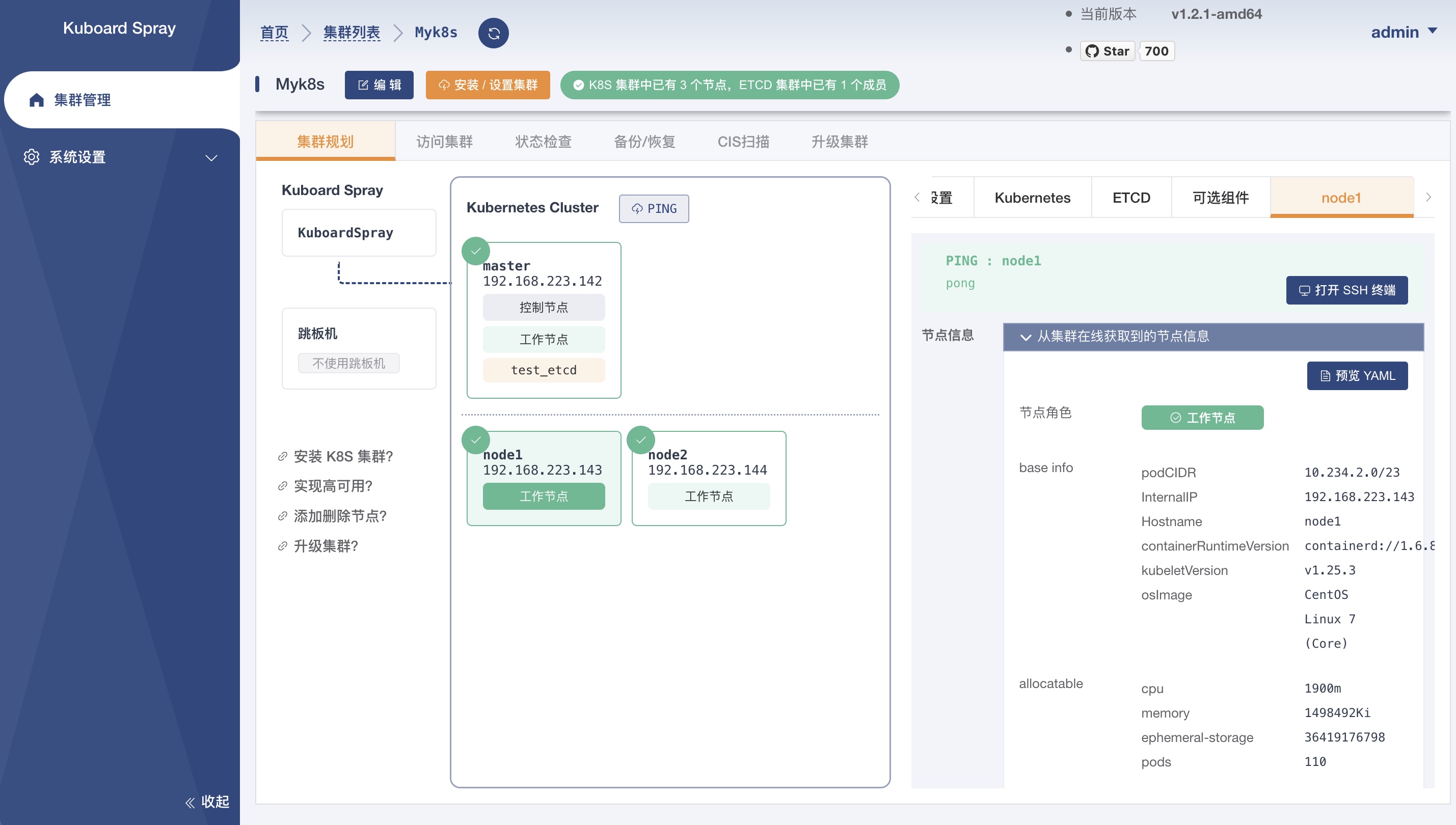
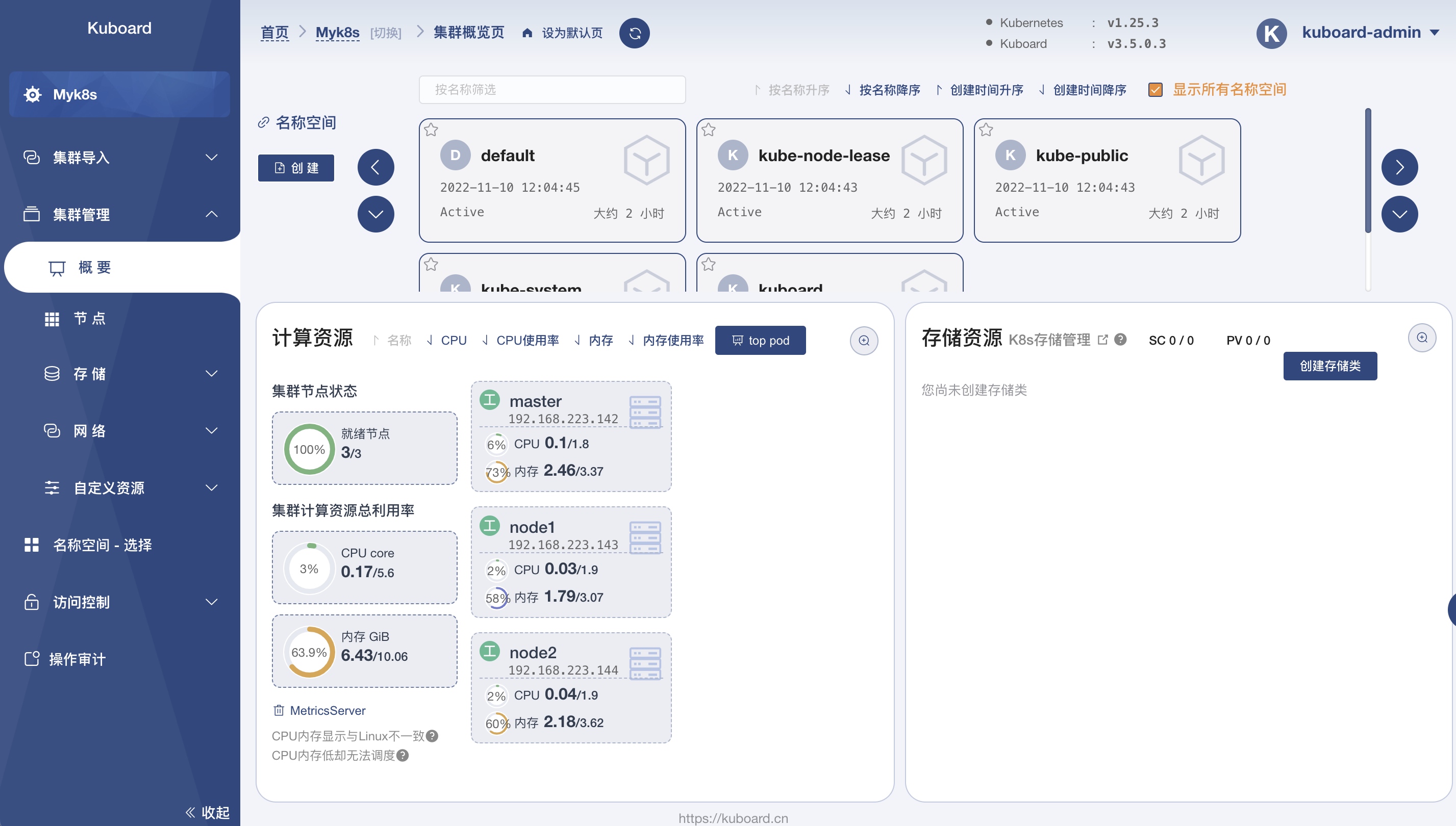
将要搭建的集群结构:
- 一个master 节点:192.168.223.142
- 两个node 节点:192.168.223.143、192.168.223.144
#K8S 集群自动安装
首先安装kuboard-spray ,它是一个可以在图形界面引导下完成 Kubernetes 高可用集群离线安装的工具。它通过 ansible / ssh 命令直接操作集群节点的操作系统,执行 Kubernetes 集群的安装、添加节点、删除节点、备份、漏洞扫描等任务。
|
|
安装成功界面(用户名 admin,默认密码 Kuboard123)
 导入Kuboard-Spray 的资源包
导入Kuboard-Spray 的资源包
 创建集群
创建集群
在集群管理界面,点击界面中的 添加集群安装计划 ,添加一台Linux 机器作为节点,然后点击安装设置集群即可。(中间可能会因为网络原因,导致失败,多试几次)
#K8S 集群手动安装
准备三台Centos 7,搭建和上图相同的集群结构,在这三台机器上都执行以下命令:
|
|
选择一台机器用作安装master节点
|
|
如果kubelet 服务启动存在问题,可参考:https://blog.51cto.com/qiangsh/4802797
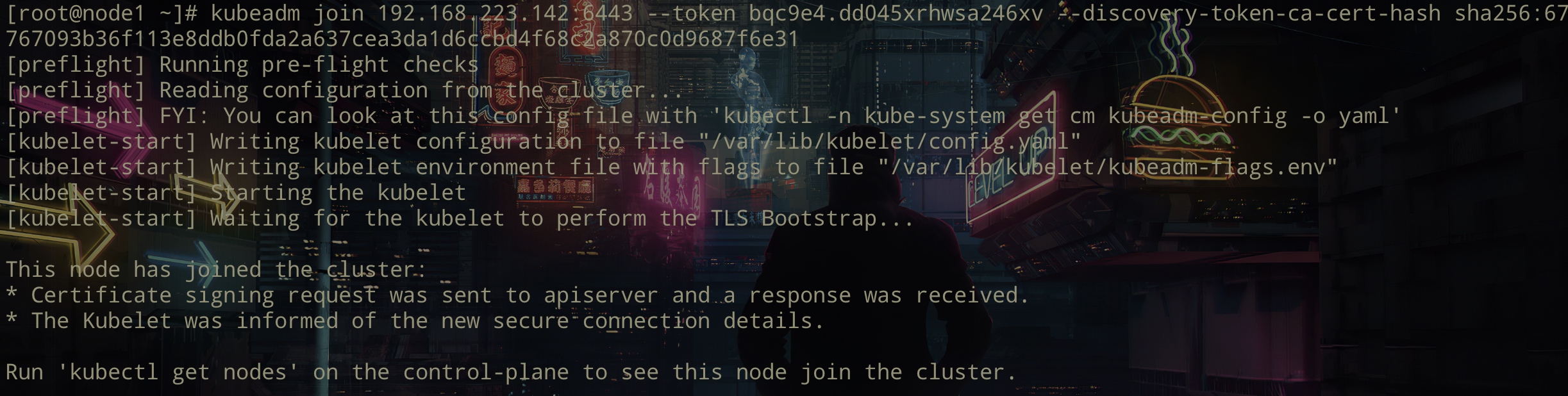
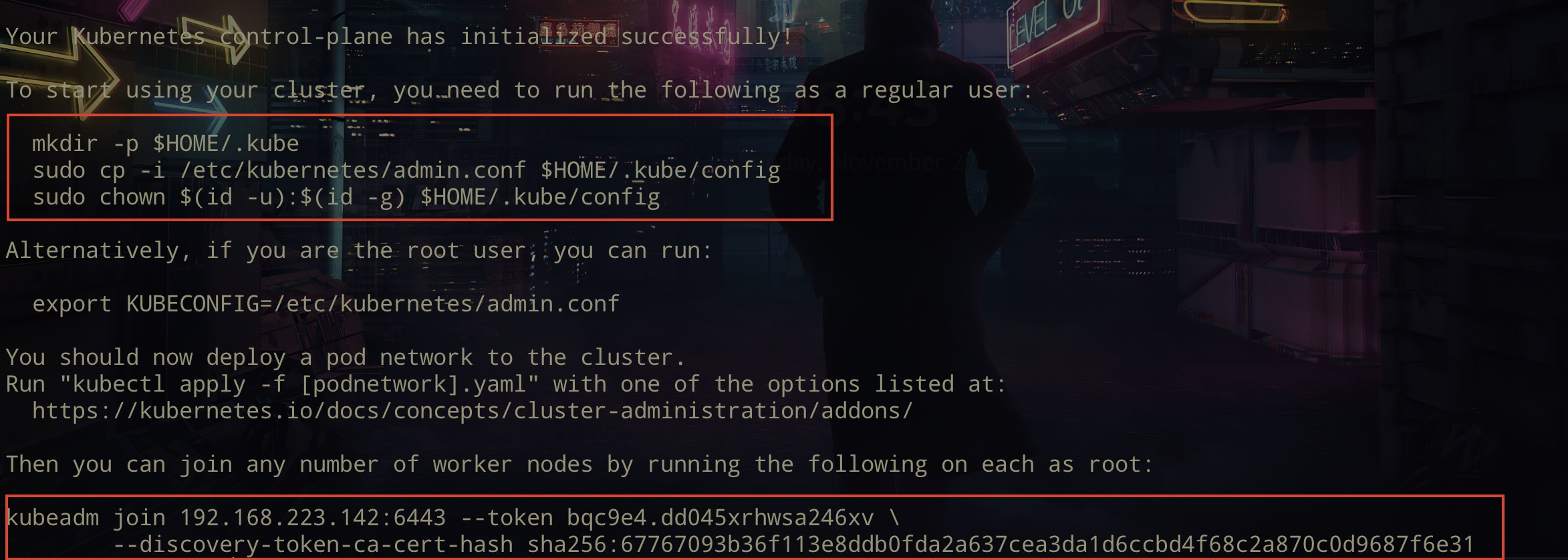 在node1和node2上执行join 命令来加入集群
在node1和node2上执行join 命令来加入集群
|
|
 安装Calico
安装Calico
|
|
修改yaml中的CALICO_IPV4POOL_CIDR字段为前面kubeadm init 中的10.20.20.0/24的值。

|
|
#Kuboard 安装(可选)
Kuboard 通过 kubernetes 的 apiserver 执行集群的日常管理操作,例如:名称空间创建、Deployment 创建修改、Service 的创建修改等,Kuboard 支持细致的权限控制(相当于kubectl 命令的图形化操作)。
Tips: kubectl 是使用 Kubernetes API 与 Kubernetes 集群的控制节点进行通信的命令行工具。
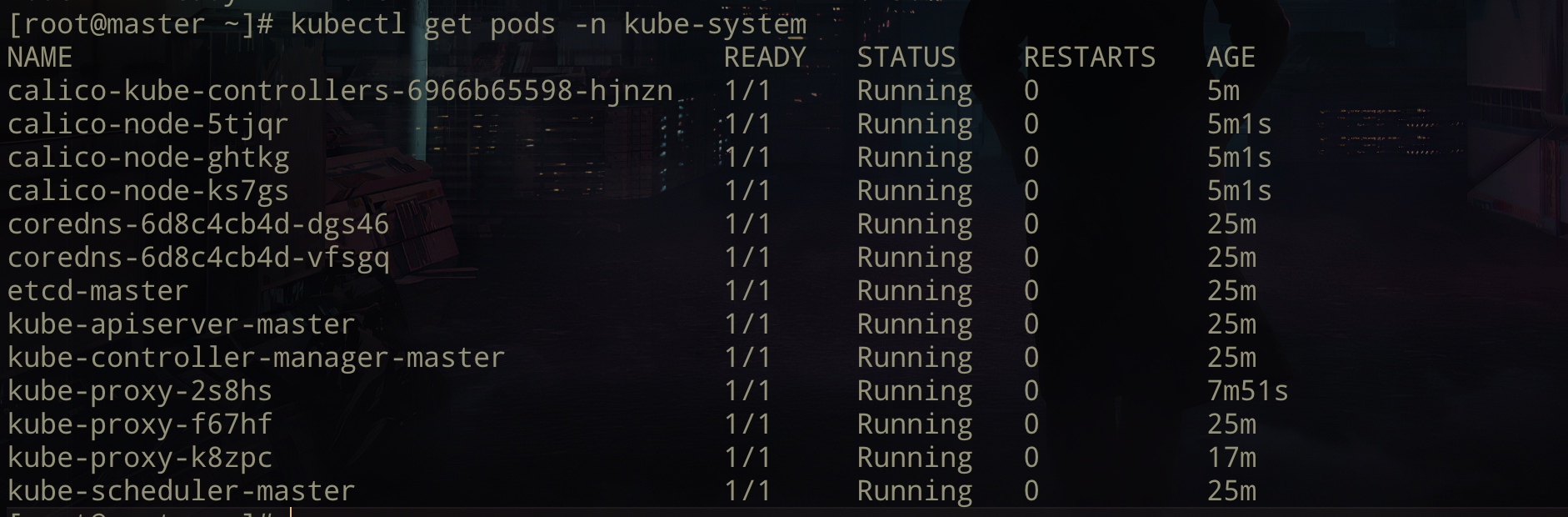
在master节点安装 kubectl apply -f https://addons.kuboard.cn/kuboard/kuboard-v3-swr.yaml
查看安装状态:kubectl get pods -n kuboard
 等待全部READY都为1/1时,表示安装完成。(此方式如果存在问题,可通过 docker 安装,下面的图是通过docker安装的)
等待全部READY都为1/1时,表示安装完成。(此方式如果存在问题,可通过 docker 安装,下面的图是通过docker安装的)
直接访问http://192.168.223.142:30080 ,用户名: admin ,密码: Kuboard123 。
#Kubernetes Dashboard 安装(可选)
Kubernetes Dashboard 是 Kubernetes 的官方 Web UI 管理工具。可以通过它向 Kubernetes 集群部署容器化应用、管理集群的资源、查看集群上所运行的应用程序、创建、修改Kubernetes 上的资源(例如 Deployment、Job、DaemonSet等),它的默认端口是30000以上随机的。
|
|
可修改recommended.yaml,添加两个参数来指定开放的端口
 开启后,直接访问master 节点的32100端口
开启后,直接访问master 节点的32100端口
 登录前需要先创建一个名为
登录前需要先创建一个名为 admin-user的 ServiceAccount,再创建一个 ClusterRolebinding,将其绑定到 Kubernetes 集群中 cluster-admin这个 ClusterRole。
|
|
使用生成的token即可登录
#基础知识
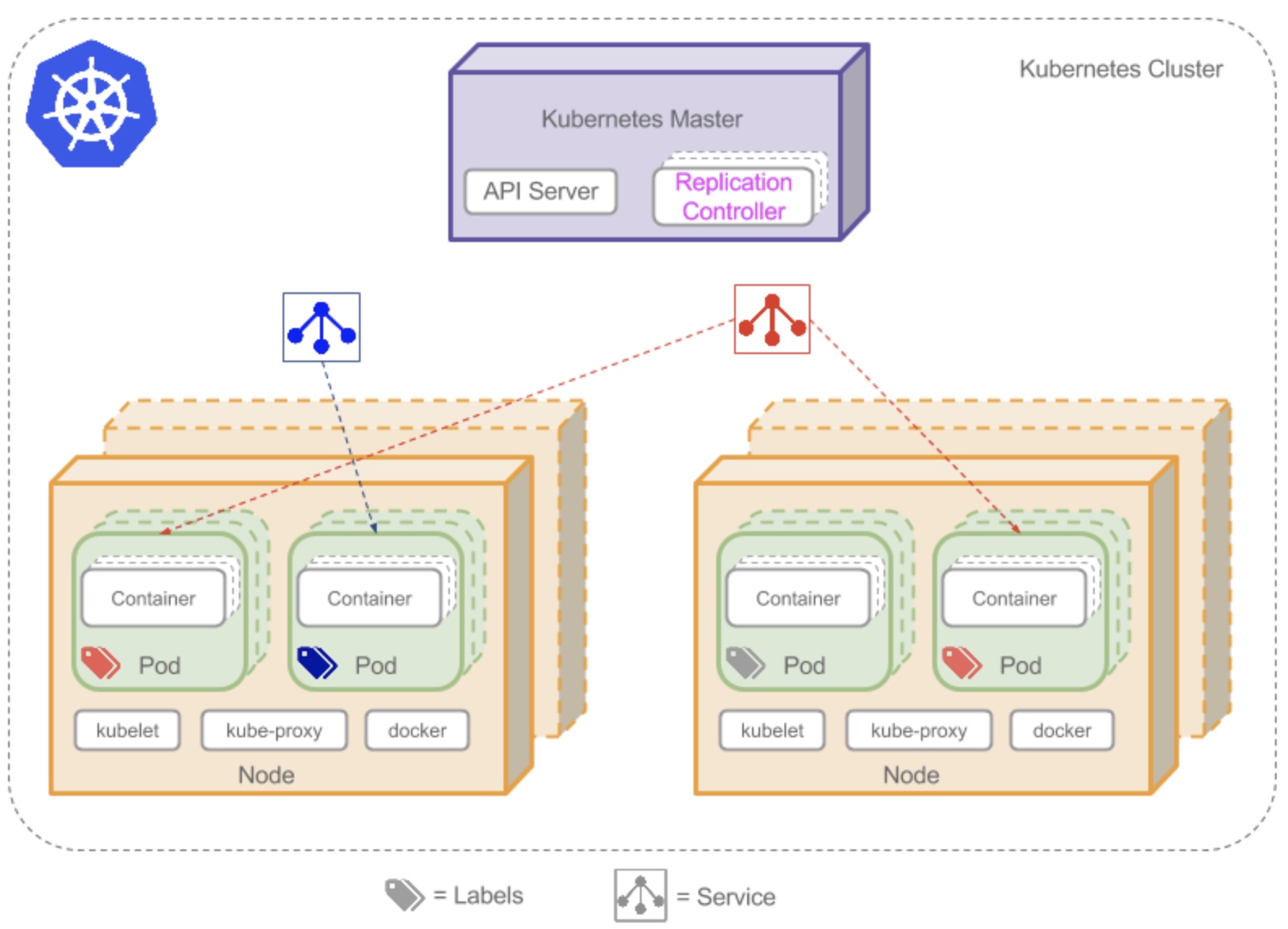
当部署完 Kubernetes,便拥有了一个完整的集群。每个集群至少有一个工作节点。工作节点会托管 Pod ,而 Pod 就是作为应用负载的组件(简单理解就是容器)。 控制节点 管理集群中的工作节点和 Pod。 在生产环境中, 一个集群通常运行多个控制节点,提供容错性和高可用性。
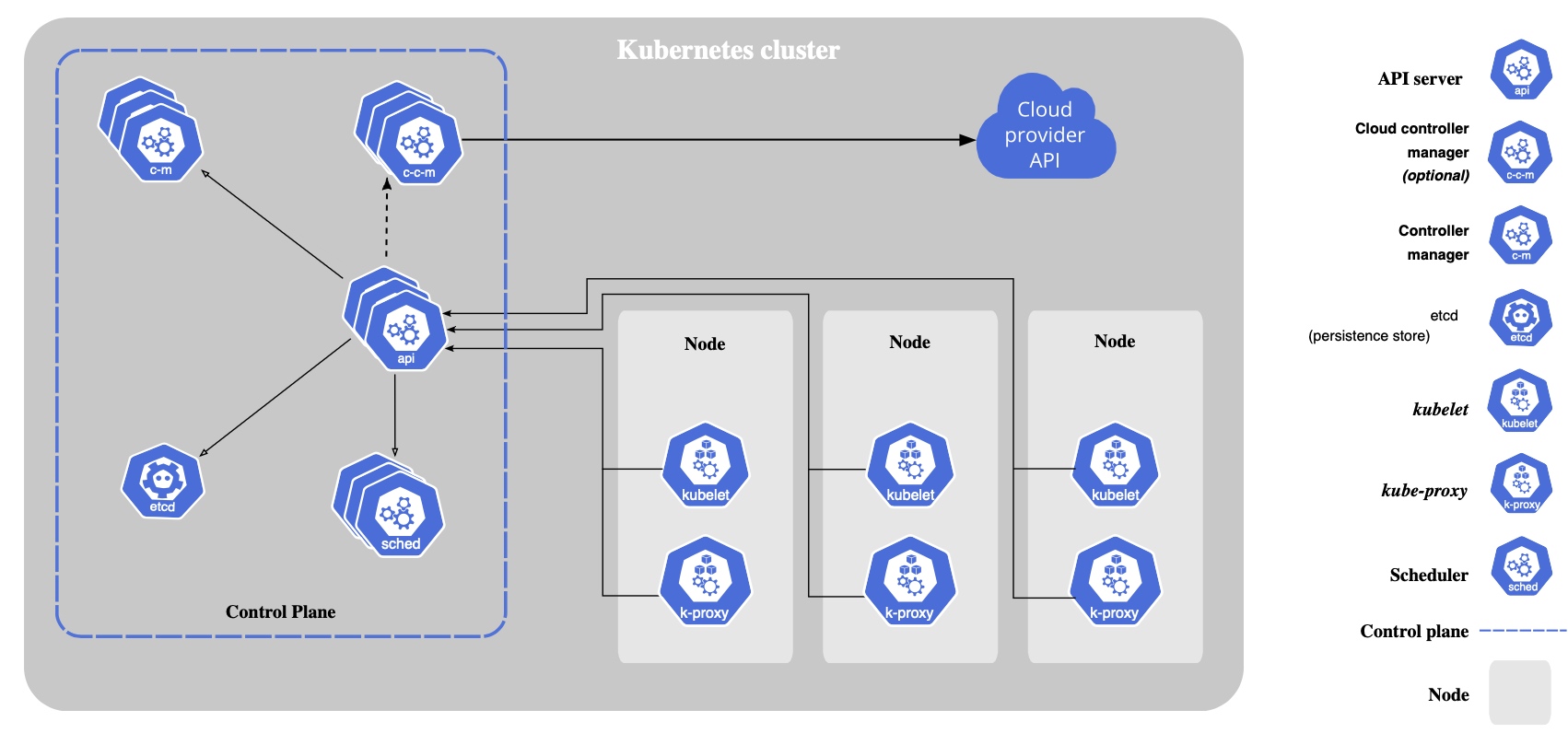
#控制节点
-
kube-apiserver
此服务负责公开 Kubernetes API,并处理请求。可以通过 Kubernetes API 查询和操纵 Kubernetes API 中对象(如:Pod、Namespace、ConfigMap 、Event)的状态。大部分操作都可以通过 kubectl 命令行接口或类似 kubeadm 这类命令行工具来执行, 这些工具在背后也是调用Kubernetes API。也可以使用 REST 调用来访问这些 API。
-
kube-scheduler
是负责监视新创建的、未指定运行节点的 Pods, 并选择节点来让 Pod 在上面运行。
-
etcd
是一致且高度可用的键值存储,用作 Kubernetes 的所有集群数据的后台数据库。
|
|
#工作节点
工作节点可以是虚拟机或物理计算机,由控制节点管理。
-
kubelet
此服务会在集群中每个工作节点(node)上运行。负责 Kubernetes 控制节点和工作节点之间通信的过程,管理 Pod 和机器上运行的容器。
-
kube-proxy
是集群中每个工作节点(node)所上运行的网络代理, 实现 Kubernetes 服务概念的一部分。它维护节点上的一些网络规则, 这些网络规则会允许从集群内部或外部的网络会话与 Pod 进行网络通信。
-
Container Runtime
在集群内每个节点上安装一个容器运行时(如 Docker)以使 Pod 可以运行在上面。
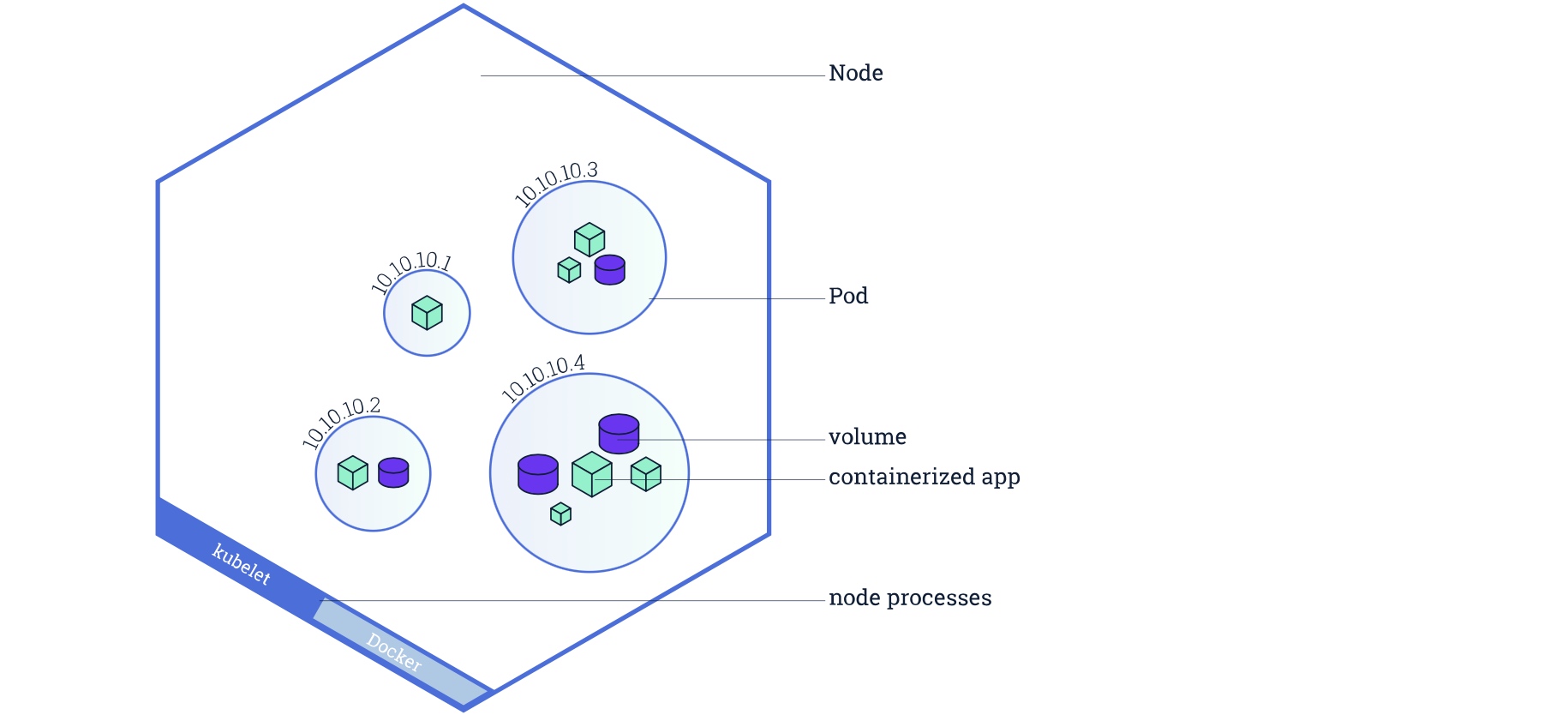
Pod 是 Kubernetes 抽象出来的,表示一组一个或多个应用程序容器(如 Docker),以及这些容器的一些共享资源。
一个 Pod 总是运行在工作节点。工作节点可以有多个 Pod 。控制节点会根据每个工作节点上可用资源的情况,自动调度 Pod(容器组)到最佳的工作节点上。如果运行实例的工作节点关机或被删除,则 Kubernetes Deployment Controller 将在群集中资源最优的另一个工作节点上重新创建一个新的实例。这提供了一种自我修复机制来解决机器故障或维护问题。
|
|
#服务(Service)
Pod(容器组)有自己的生命周期。当工作节点故障时,节点上运行的 Pod 也会消失。然后Deployment 可以通过创建新的 Pod 来动态地将群集调整回原来的状态,以使应用程序保持运行。
Service 将外部请求路由到一组 Pod 中,它提供了一个抽象层,使得 Kubernetes 可以在不影响服务调用者的情况下,动态调度容器组(在容器组失效后重新创建容器组,增加或者减少同一个 Deployment 对应容器组的数量等)。一个 Service 识别有哪些Pod有相同特征, 通常由 LabelSelector(标签选择器)来决定。
Service有三种选项暴露应用程序的入口,可以通过设置应用程序配置文件中的Service 项的spec.type 值来调整
-
ClusterIP(默认)
在群集中的内部IP上公布服务,这种方式的 Service(服务)只在集群内部可以访问到。
-
NodePort
使用 NAT 在集群中每个的同一端口上公布服务。这种方式下,可以通过访问集群中任意节点+端口号的方式访问服务
<NodeIP>:<NodePort>。此时 ClusterIP 的访问方式仍然可用。 -
LoadBalancer
在云环境中(需要云供应商可以支持)创建一个集群外部的负载均衡器,并为使用该负载均衡器的 IP 地址作为服务的访问地址。此时 ClusterIP 和 NodePort 的访问方式仍然可用。
|
|
#Kubernetes 对象
Kubernetes 对象是持久化的实体。 Kubernetes 使用这些实体去表示整个集群的状态。创建 Kubernetes 对象时,必须提供对象的 spec,用来描述该对象的期望状态, 以及关于对象的一些基本信息(例如名称)。
当使用 Kubernetes API 创建对象时, API 请求必须在请求本体中包含JSON 格式的信息。 大多数情况下,需要 yaml 文件为 kubectl 提供这些信息。 kubectl在发起 API 请求时,将这些信息转换成 JSON 格式。
 使用kubectl 通过yaml 创建此对象。
使用kubectl 通过yaml 创建此对象。
kubectl apply -f https://k8s.io/examples/application/deployment.yaml
#命名空间(namespace)
命名空间是Kubernetes提供的组织机制,用于给集群中的任何对象组进行分类、筛选和管理。它将同一集群中的资源划分为相互隔离的组(同一命名空间内的资源名称要唯一),它适用于存在很多跨多个团队或项目的用户的场景。
有以下使用场景:
- 将命名空间映射到团队或项目上,一般是为每个单独的项目或者团队创建一个命名空间。
- 使用命名空间对生命周期环境进行分区,非常适合在集群中划分开发、staging以及生产环境。
- 使用命名空间隔离不同的使用者。
默认的命名空间
-
default
在向集群中添加对象而不提供命名空间时,它会被放入此默认命名空间中。
-
kube-public
此命名空间目的是让所有具有或不具有身份验证的用户都能全局可读。这对于公开bootstrap 组件所需的集群信息非常有用,它主要是由Kubernetes自己管理。
-
kube-system
此命名空间用于Kubernetes 管理的Kubernetes组件,一般由系统直接管理,应避免向该命名空间添加普通的工作负载。
-
kube-node-lease 集群之间的心跳维护
|
|
#认证与授权
Kubernetes 的认证策略是:通过 authentication plugin 认证发起 API 请求的用户身份,认证方式有 client certificates、bearer tokens、authenticating proxy、HTTP basic auth。
kubernetes 在1.5 版的时候引入了RBAC(Role Base Access Control)的权限控制机制。需要在 apiserver 中添加参数--authorization-mode=RBAC来启用RBAC。从 1.16 版本起,默认启用 RBAC 访问控制策略。
 API Server 目前支持以下几种授权策略:
API Server 目前支持以下几种授权策略:
AlwaysDeny、AlwaysAllow、ABAC(基于属性的访问控制)、Webhook(通过调用外部REST服务对用户进行授权)、RBAC(基于角色的访问控制)、Node(用于对kubelet发出的请求进行访问控制)
RBAC 是目前k8s中最主要的鉴权方式,下面会着重讲解:
#用户分类
K8s的用户共分两种:一种是普通用户,一种是ServiceAccount(服务帐户)。只有ServiceAccount 才在Kubernetes中以资源的形式存在,用户、组并不会以资源的形式存在,它们只是一个字符串,在使用的地方如RoleBinding 时被引用,不能通过集群内部的 API 来进行管理。
ServiceAccount 是由Kubernetes API 管理的用户。它们绑定到特定的命名空间,并由API服务器自动创建或通过API调用手动创建。服务帐户与存储为Secrets的一组证书相关联,这些凭据被挂载到pod中,以便集群进程与Kubernetes API通信。(登录dashboard时,就使用的就是ServiceAccount)
kubectl -n kube-system get sa 查看指定命名空间下的ServiceAccount 账号。
#Role & RoleBinding (角色与角色绑定)
在RABC API中,通过如下的步骤进行授权:
- 定义角色:在定义角色时会指定此角色对于资源的访问控制的规则。
- 绑定角色:将主体与角色进行绑定,对用户进行访问授权。
整体逻辑如下图:
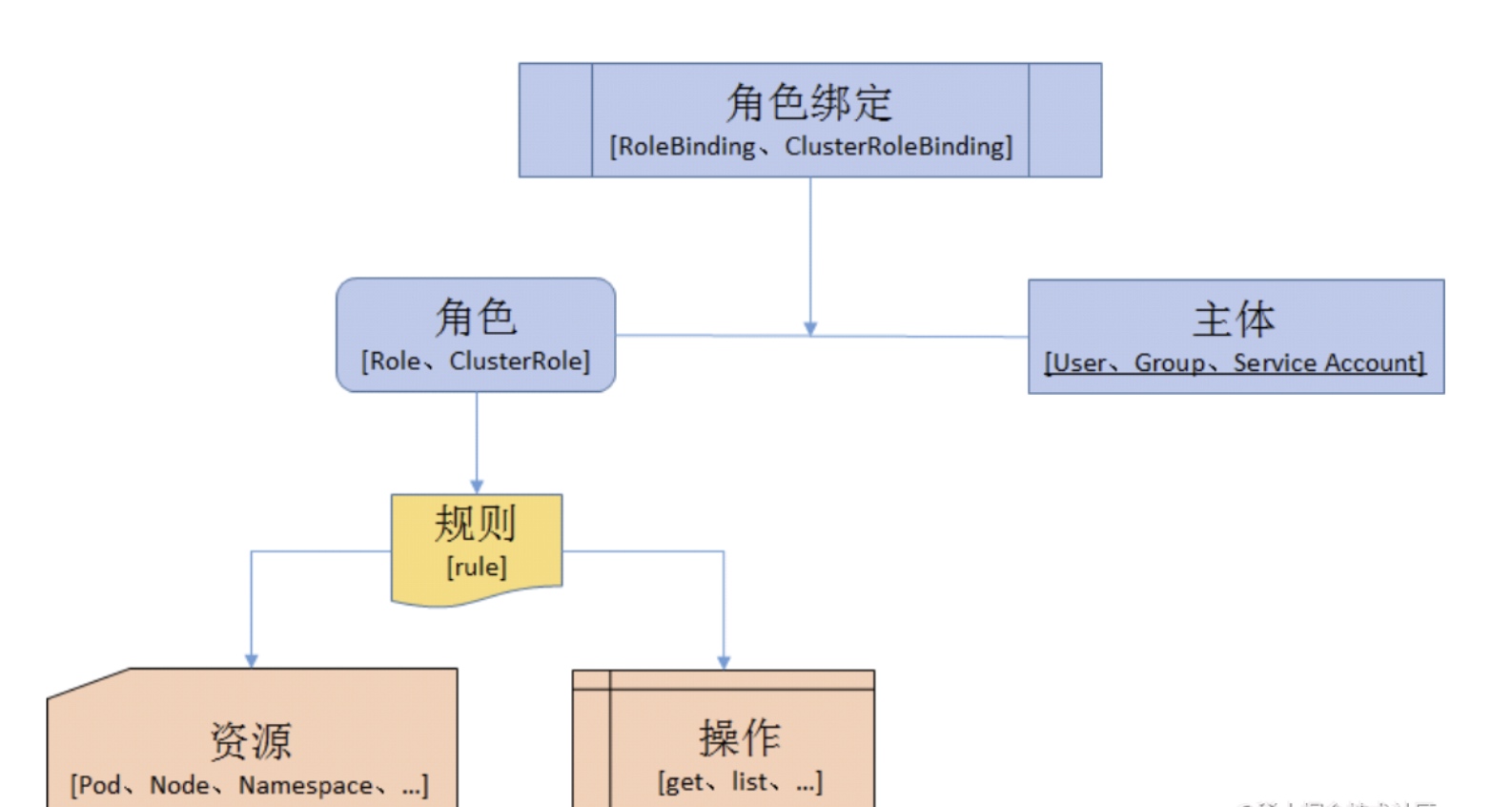 下面介绍一下三种概念的构成:
下面介绍一下三种概念的构成:
- Role(角色)分为:
- Role:授权特定命名空间的访问权限
- ClusterRole:授权所有命名空间的访问权限
- RoleBinding(角色绑定)分为:
- RoleBinding:将角色绑定到主体(即subject)
- ClusterRoleBinding:将集群角色绑定到主体
- subject(主体)分为:
- User:用户
- Group:用户组
- ServiceAccount:服务账号
角色绑定和集群角色绑定,简单来说就是把声明的 Subject 和 Role 进行绑定的过程(给某个用户绑定上操作的权限),二者的区别也是作用范围的区别:RoleBinding 只会影响到当前namespace 下面的资源操作权限,而 ClusterRoleBinding 会影响到所有的namespace。
查询命名空间下的角色:kubectl get role -n kube-system
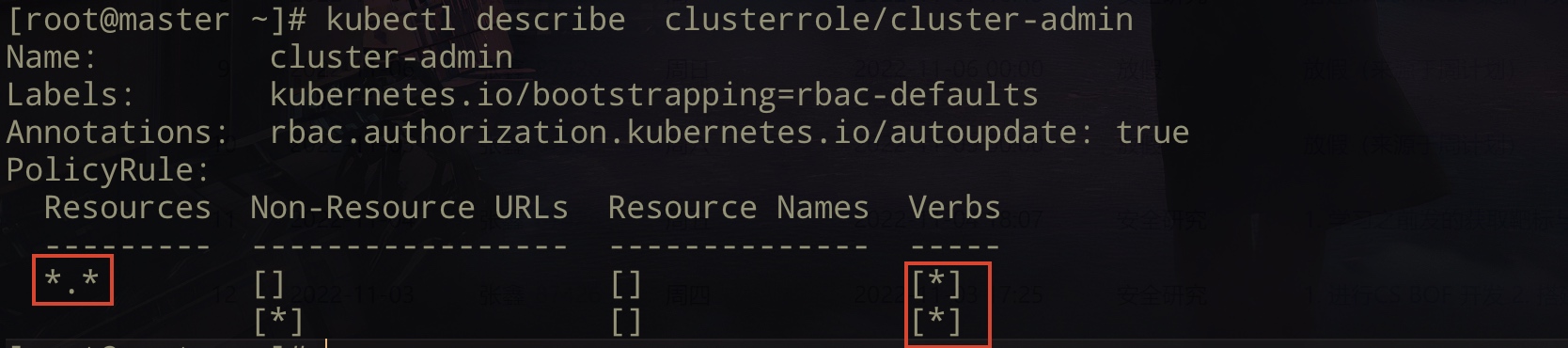
查询集群下的角色:kubectl get clusterrole ,cluster-admin 代表集群中的最高权限角色。
 查询指定角色信息:
查询指定角色信息:kubectl describe clusterrole/cluster-admin